
AI原生健康硬件公司完成近亿元融资,主打尿液检测?
AI原生健康硬件公司完成近亿元融资,主打尿液检测?硬氪获悉,AI 原生健康硬件公司「杉木SHANMU」近日完成近亿元 A 轮融资,本轮由石溪资本(兆易创新旗下战投基金)领投,韶音科技、博将资本、涌铧投资、上海天使会等多家机构联合参投,老股东甘洁教授旗下知行一号基金和万物为资本追加本轮投资。庚辛资本为本轮财务顾问。
来自主题: AI资讯
8395 点击 2026-05-07 12:02
 搜索
搜索
硬氪获悉,AI 原生健康硬件公司「杉木SHANMU」近日完成近亿元 A 轮融资,本轮由石溪资本(兆易创新旗下战投基金)领投,韶音科技、博将资本、涌铧投资、上海天使会等多家机构联合参投,老股东甘洁教授旗下知行一号基金和万物为资本追加本轮投资。庚辛资本为本轮财务顾问。

《读佳》获知,蚂蚁集团正在开发一款名为“Muse”的产品,该产品或为灵感创作类的AI产品,主打让灵感轻松成真,产品的中文名可能叫做“巧妙思”,由于产品还在开发,具体产品形态及相关信息请以官方为准。
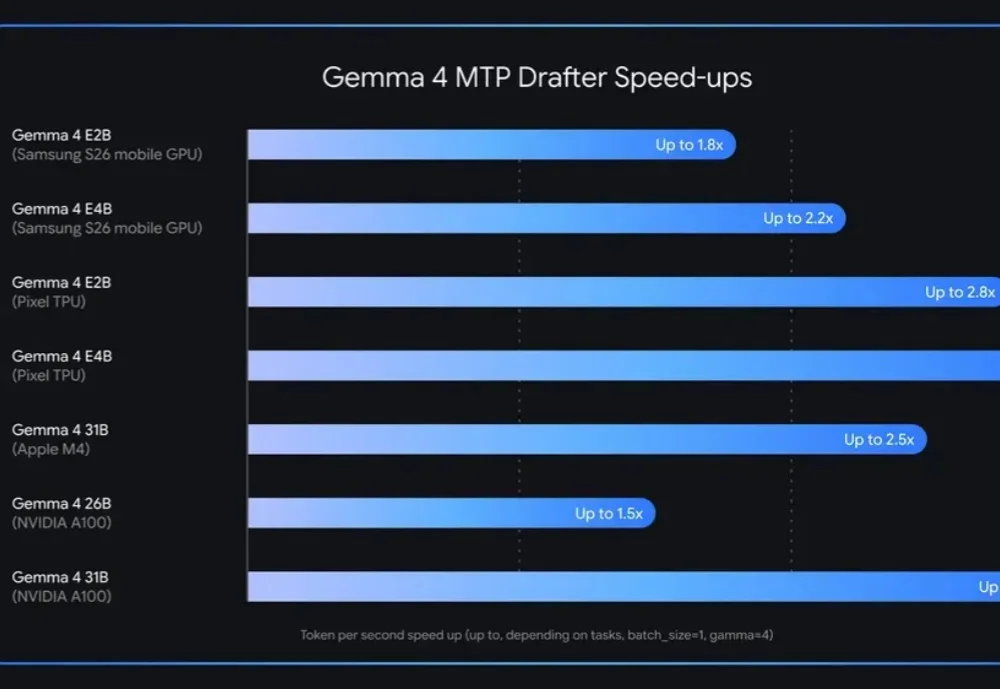
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。

4 月 9 日,Anthropic 在 X 上宣布 Claude Managed Agents 上线。同一天,一位 ID 叫 @jiayuan_jy 的中国创业者也发了一条推,“We created the open source version of Claude Managed Agents. Introducing Multica.”

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
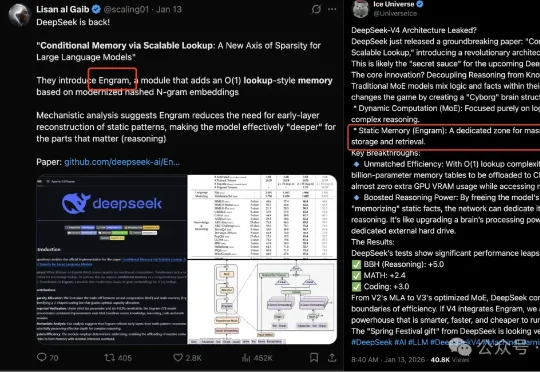
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
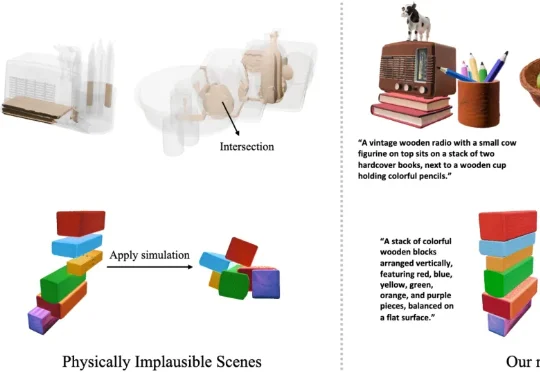
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。

据The Verge等多家外媒报道,今天凌晨,埃隆·马斯克(Elon Musk)与OpenAI CEO萨姆·奥尔特曼(Sam Altman)的世纪庭审在加州奥克兰联邦法院进入开庭陈词阶段。当天,马斯克身穿黑色西装、系黑色领带,出现在联邦法院。马斯克方、OpenAI方与微软方依次发表开庭陈词,随后马斯克作为本案第一证人进行举证。

腾讯混元团队提出了 Multi-Stream Scene Script(MTSS),一种全新的视频描述范式 —— 将传统的 "一段话描述整个视频" 升级为 "多流结构化剧本",通过 Stream Factorization 和 Relational Grounding 两大核心原则,让视频描述既忠实又可扩展,在视频理解和生成任务中均取得显著提升。

张佳圆带着他的新产品 Multica 一周斩获 GitHub 1.2w Star回来了。这一次,他想探索的是: 当 AI Agent 已经足够好,一个团队要怎么和多个 Agent 丝滑地协作?Multica 致敬的是 1964 年的操作系统 Multics——那个最终失败、但启发了 Unix 世界半个世纪的“多人、多任务”先驱。今天,它正在创造新的历史。