ICML 2026 | 多智能体系统也能搭积木?Agent Primitives让MAS走向模块化复用
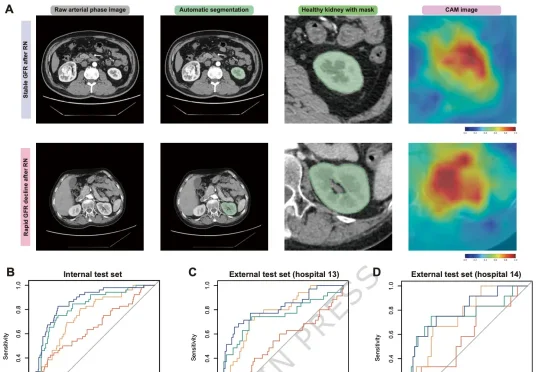
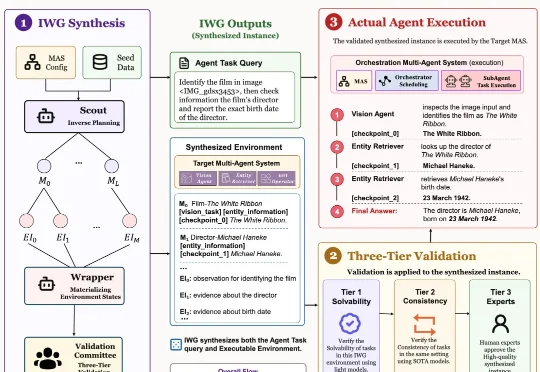
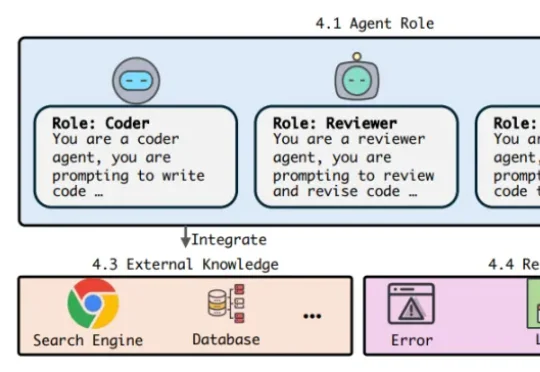
ICML 2026 | 多智能体系统也能搭积木?Agent Primitives让MAS走向模块化复用多智能体系统(Multi-Agent Systems,MAS)展示了令人印象深刻的能力:一个模型负责提出方案,另一个模型进行批评,还有模型承担投票、规划或执行。通过角色分工和多轮协作,系统能够解决单个模型难以稳定完成的数学推理、代码生成和知识问答任务。
来自主题: AI技术研报
7805 点击 2026-07-21 17:05