微软出招!新模型数学超GPT-4o编程胜Llama3.3,训练新范式引热议:midtraining
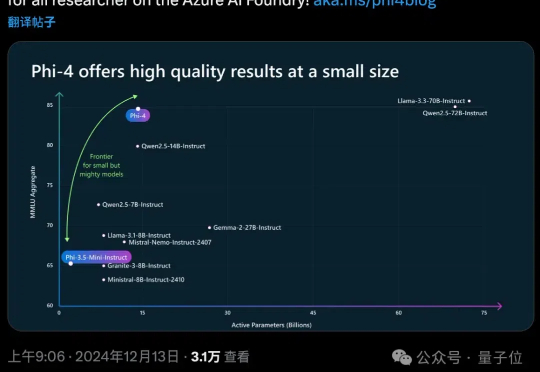
微软出招!新模型数学超GPT-4o编程胜Llama3.3,训练新范式引热议:midtrainingOpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。
来自主题: AI技术研报
9050 点击 2024-12-13 15:14
 搜索
搜索
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。
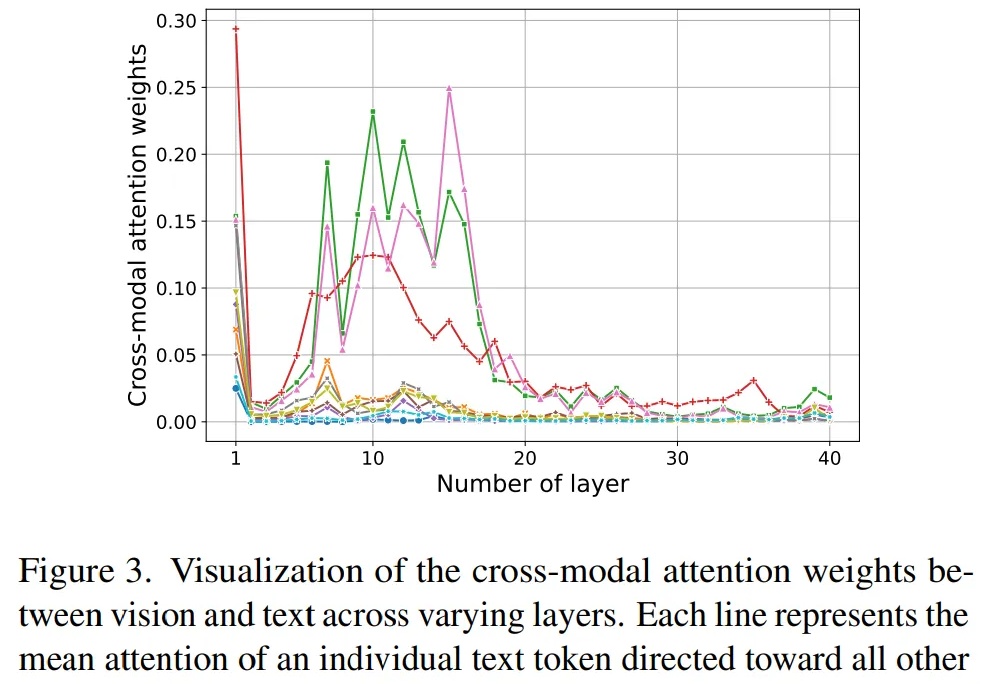
尽管近期 Qwen2-VL 和 InternVL-2.0 的出现将开源多模态大模型的 SOTA 提升到了新高度,但巨大的计算开销限制了其在很多场景下的应用。
自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。
国产大模型,最近有点卷。
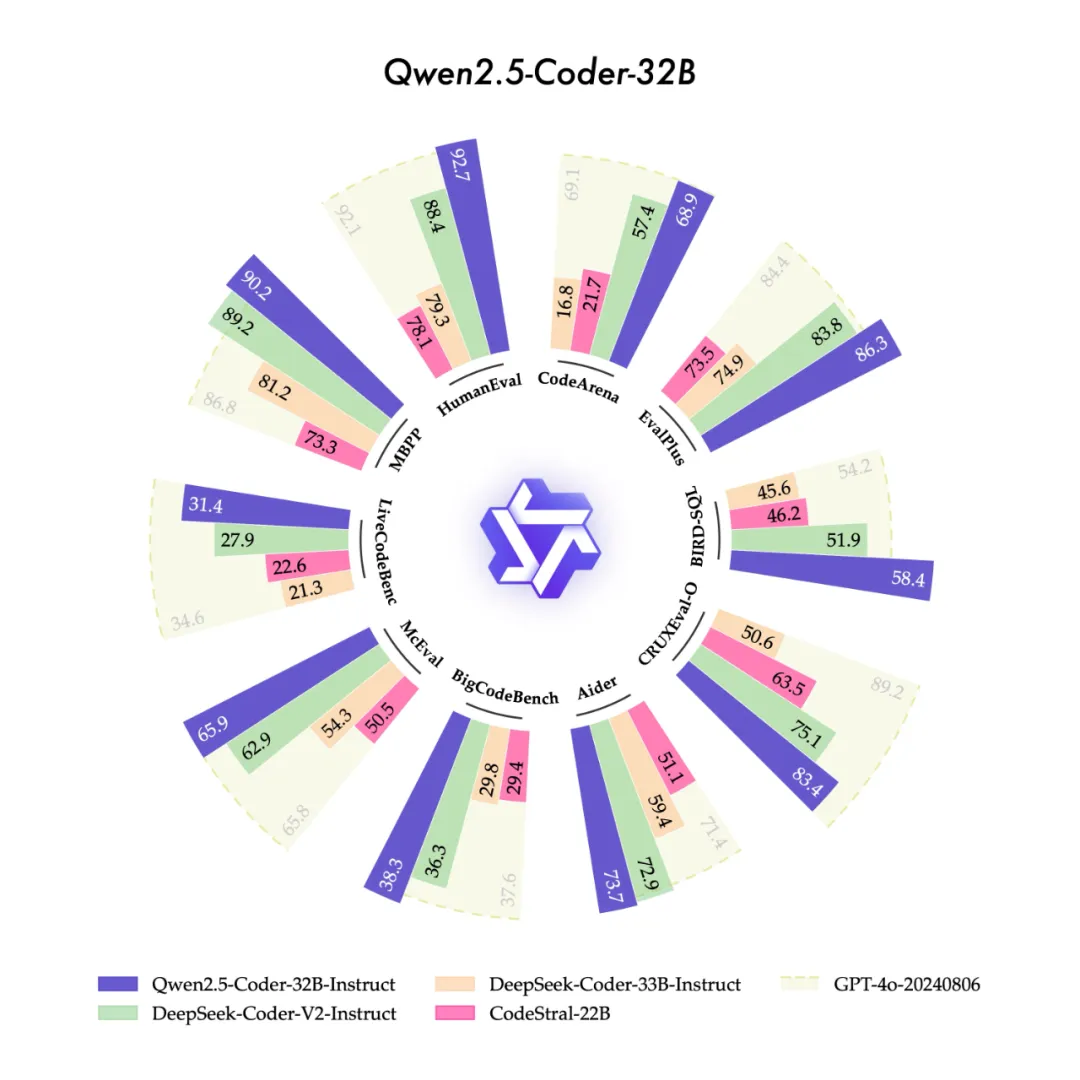
今天,我们很高兴开源“强大”、“多样”、“实用”的Qwen2.5-Coder全系列模型,致力于持续推动Open CodeLLMs的发展。

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。

又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!

欧洲的OpenAI,也不Open了。

实话说,我一直没想明白阿里为什么会在大模型这个赛道,成为中国版的Meta。
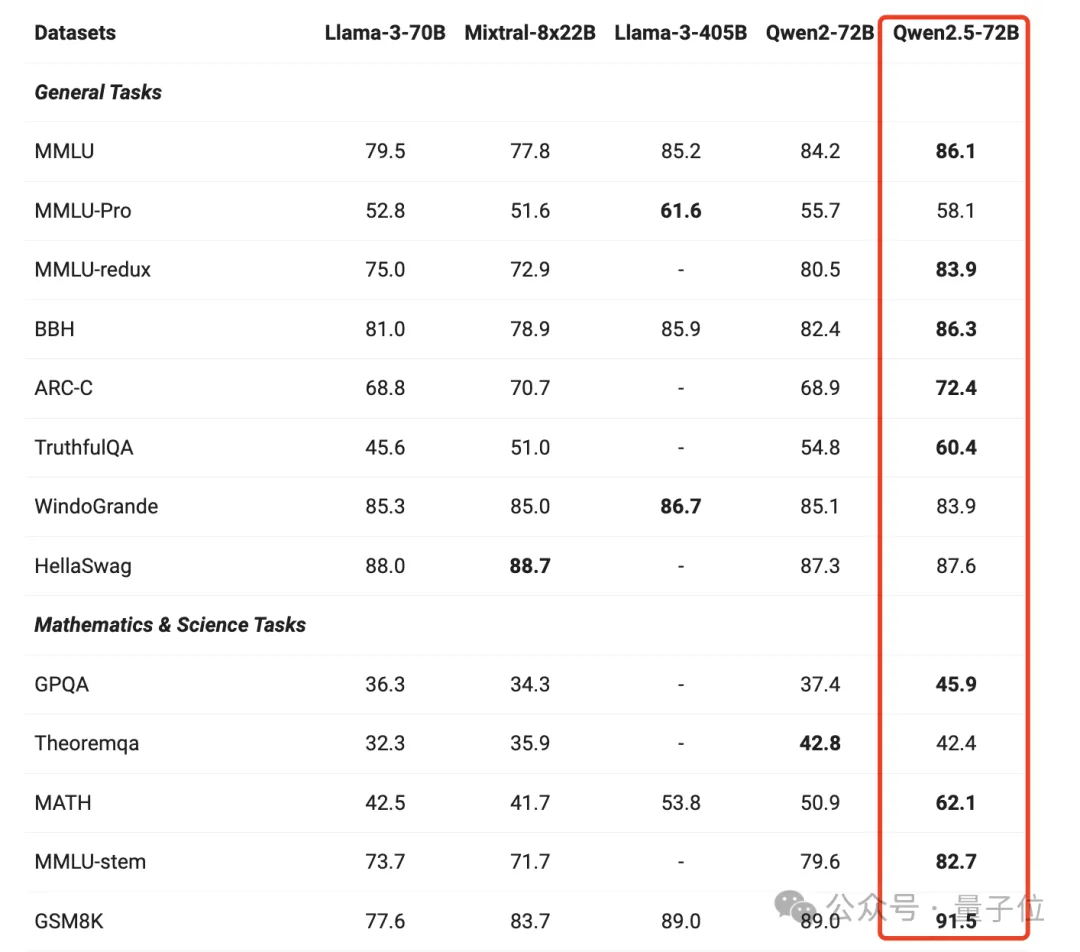
击败LIama3!Qwen2.5登上全球开源王座。 而后者仅以五分之一的参数规模,就在多任务中超越LIama3 405B。