
前清华创协副主席、韶音工程师创业拿下千万级融资,首款产品:AI运动头带
前清华创协副主席、韶音工程师创业拿下千万级融资,首款产品:AI运动头带北京脑回录科技有限公司(Nanoloop)宣布完成千万级种子 + 轮融资。本轮融资由南山战新投领投。此前,公司曾获得奇绩创坛种子轮投资。本轮资金将主要用于运动脑机接口核心技术迭代、Nuromova 智能运动头带工程化量产、真实运动场景脑电数据资产建设及国内外市场拓展。
来自主题: AI资讯
7999 点击 2026-05-10 12:47
 搜索
搜索
北京脑回录科技有限公司(Nanoloop)宣布完成千万级种子 + 轮融资。本轮融资由南山战新投领投。此前,公司曾获得奇绩创坛种子轮投资。本轮资金将主要用于运动脑机接口核心技术迭代、Nuromova 智能运动头带工程化量产、真实运动场景脑电数据资产建设及国内外市场拓展。
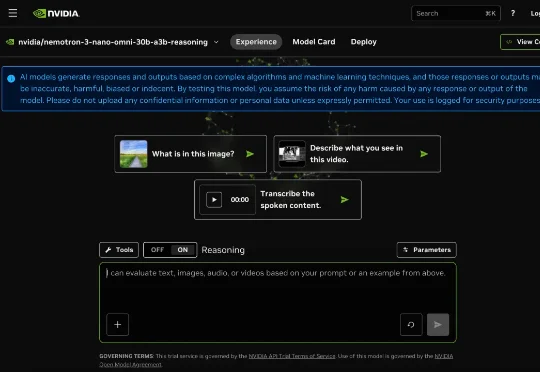
英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。

“这是我过去四个月一直在研究的东西!”

GPT Image 2的横空出世,直接暴打 Nano Banana 2,现在,真假难辨的照片和梗图已经满天飞了。超强的文字渲染和封神的设计能力,直接让它颠覆了众多行业,这一刻起,互联网的信任体系彻底洗牌!

北京时间凌晨 3 点,直播准时开始,OpenAI 发布了 ChatGPT Images 2.0。据介绍,「ChatGPT Images 2.0 是下一步进化:一个最先进的模型,能够处理复杂的视觉任务,并生成精确、可直接使用的视觉内容。」

4 月初,LM Arena 评测平台上出现了三个匿名图像模型,代号分别是 maskingtape-alpha、packingtape-alpha、gaffertape-alpha。几小时后它们消失了。OpenAI 官方还没有正式宣布这个模型,但根据 API 返回的元数据和用户侧的测试记录,它已经有了一个被广泛接受的名字:GPT Image 2。

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。
Lovart是一个很好的AI产品,不仅是它能让你便宜用Nano banana🍌,更重要的是……好吧我编不下去了,Lovart的主要优点就是便宜用Nano banana,功能主要是🍌中转站。

深夜,OpenAI祭出「双子星」GPT-5.4 mini和nano,实力逼近满血版,速度性价比拉满,用来编码、当「龙虾」主力真香!
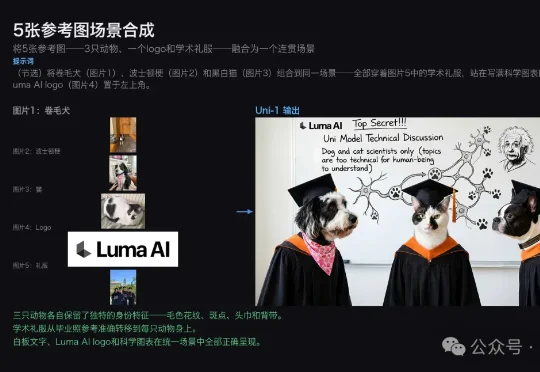
刚刚,Luma AI甩出全新模型Uni-1,正面对标谷歌Nano Banana Pro和GPT Image 1.5。Uni-1是一个统一的图像理解与生成模型。在官方展示中,Uni-1具备角色姿态迁移、故事板生成、草稿+材质结合参考生成、草稿转漫画、多参考图场景合成、草稿引导的照片编辑、UV贴图生成、带有文字的贺卡海报生成等诸多能力。