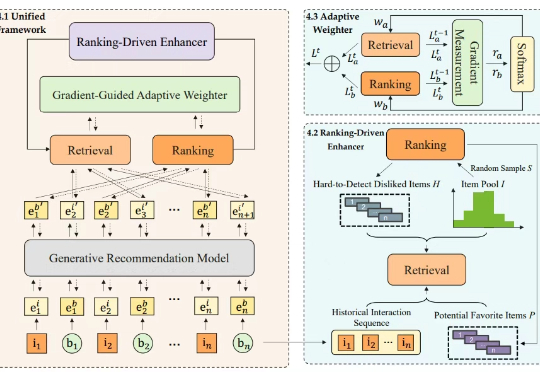
打破推荐系统「信息孤岛」!中科大与华为提出首个生成式多阶段统一框架,性能全面超越 SOTA
打破推荐系统「信息孤岛」!中科大与华为提出首个生成式多阶段统一框架,性能全面超越 SOTA在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘
来自主题: AI技术研报
7288 点击 2025-06-21 12:53
 搜索
搜索
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘

生成图像这件事,会推理的AI才是好AI。 举个例子,以往要是给AI一句这样的Prompt: (3+6)条命的动物。 我们人类肯定一眼就知道是猫咪,但AI的思考过程却是这样的:

WhobotAl电话数字员工会尽力模仿真人边对话边操作的场景。
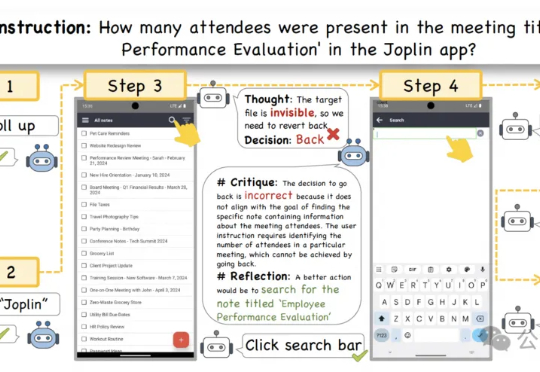
GUI智能体总是出错, 甚至是不可逆的错误。 即使是像GPT-4o这样的顶级多模态大模型,也会因为缺乏常识而在执行GUI任务时犯错。在它即将执行错误决策时,需要有人提醒它出错了。
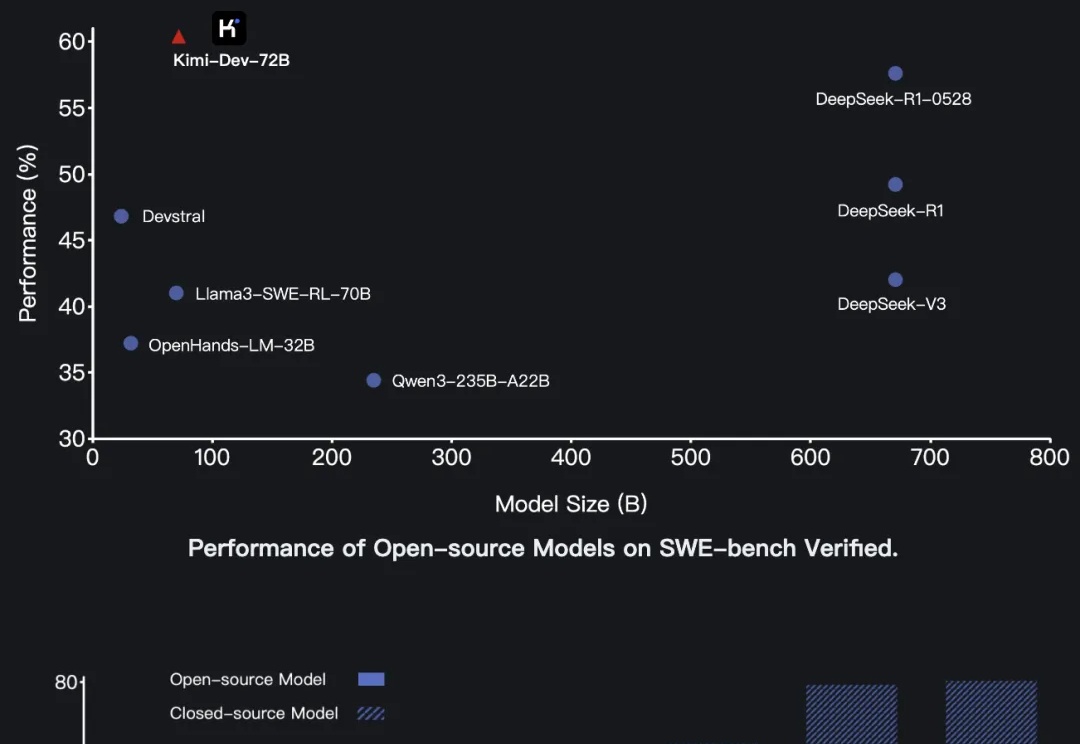
深夜,沉寂已久的Kimi突然发布了新模型—— 开源代码模型Kimi-Dev,在SWE-bench Verified上以60.4%的成绩取得开源SOTA。
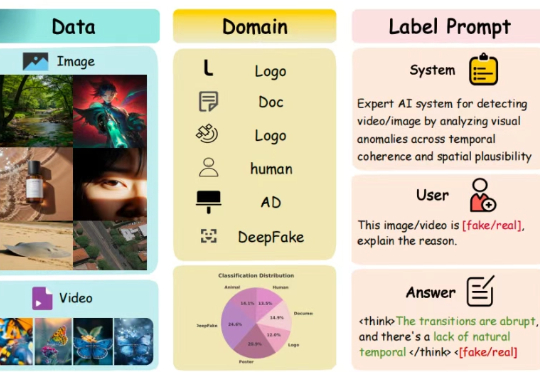
想象一下:你正在浏览社交媒体,看到一张震撼的图片或一段令人震撼的视频。它栩栩如生,细节丰富,让你不禁信以为真。但它究竟是真实记录,还是由顶尖 AI 精心炮制的「杰作」?如果一个 AI 工具告诉你这是「假的」,它能进一步解释理由吗?它能清晰指出图像中不合常理的光影,或是视频里一闪而过的时序破绽吗?
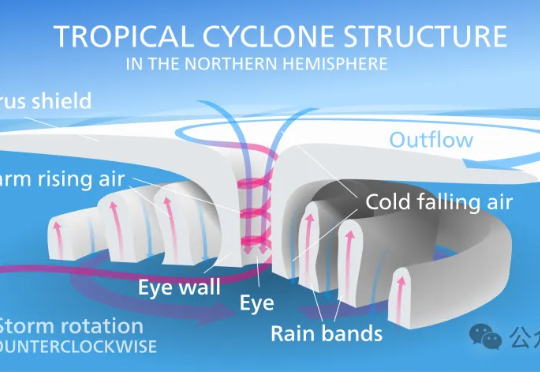
昨天,谷歌DeepMind与谷歌研究团队正式推出交互式气象平台Weather Lab,用于共享人工智能天气模型。在热带气旋路径预测方面,谷歌这次的新模型刷新SOTA,是首个在性能上明确超越主流物理模型的AI预测模型。

4月份,李飞飞教授领先编制的《2025年人工智能指数报告》提供的数据显示,2024年全年具有特殊影响力的模型(Notable AI models)当中,排名前5的几乎都来自美国、中国的科技巨头。

想象一下,你是一位游戏设计师,正在为一个奇幻 RPG 游戏搭建场景。你需要创建一个 "精灵族树屋村落"—— 参天古木和树屋、发光的蘑菇路灯、半透明的纱幔帐篷... 传统工作流程中,这可能需要数周时间:先手工建模每个 3D 资产,再逐个调整位置和材质,最后反复测试光照效果…… 总之就是一个字,难。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。