AI第一次科研竞赛中击败人类!Opus 4.7狂飙2930步创世界纪录
AI第一次科研竞赛中击败人类!Opus 4.7狂飙2930步创世界纪录Prime Intellect把Opus 4.7和GPT 5.5关进H200集群,不给人类指导,跑了1万次实验。结果:AI第一次在科研竞赛中打破人类纪录。2930步,递归自改进的卢比孔河,被跨过了。
来自主题: AI资讯
9188 点击 2026-05-15 16:55
 搜索
搜索
Prime Intellect把Opus 4.7和GPT 5.5关进H200集群,不给人类指导,跑了1万次实验。结果:AI第一次在科研竞赛中打破人类纪录。2930步,递归自改进的卢比孔河,被跨过了。
1天前,2026年4月,Primepoint完成了$10M种子轮融资。对一家成立仅两年、团队不足10人的公司而言,这个数字不算小。更值得关注的是投资人结构:深度学习先驱Yann LeCun亲自下注,多家专注建筑科技的头部VC联合跟投。

在经济学和博弈论的世界里,找到「纳什均衡」往往意味着找到了复杂局势下的最优解。多所顶尖高校的研究人员开发出了一位名为PrimeNash的「AI数学家」,不仅能像人类专家一样推导公式,还能解决许多连传统算法都束手无策的复杂博弈难题,成果已发表在Cell Press旗下的交叉学科期刊Nexus上。

最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。

不得了,这个名叫Gauss(高斯)的新AI Agent,有点杀疯了的感觉。 因为它只用了三周的时间,就完成了陶哲轩和Alex Kontorovich提出的数学挑战——在Lean中形式化强素数定理(Prime Number Theorem,PNT)。

强化学习核心是什么?Karpathy一语道破——环境。全新开源Environments Hub横空出世,为强化学习训练带去革命性突破。

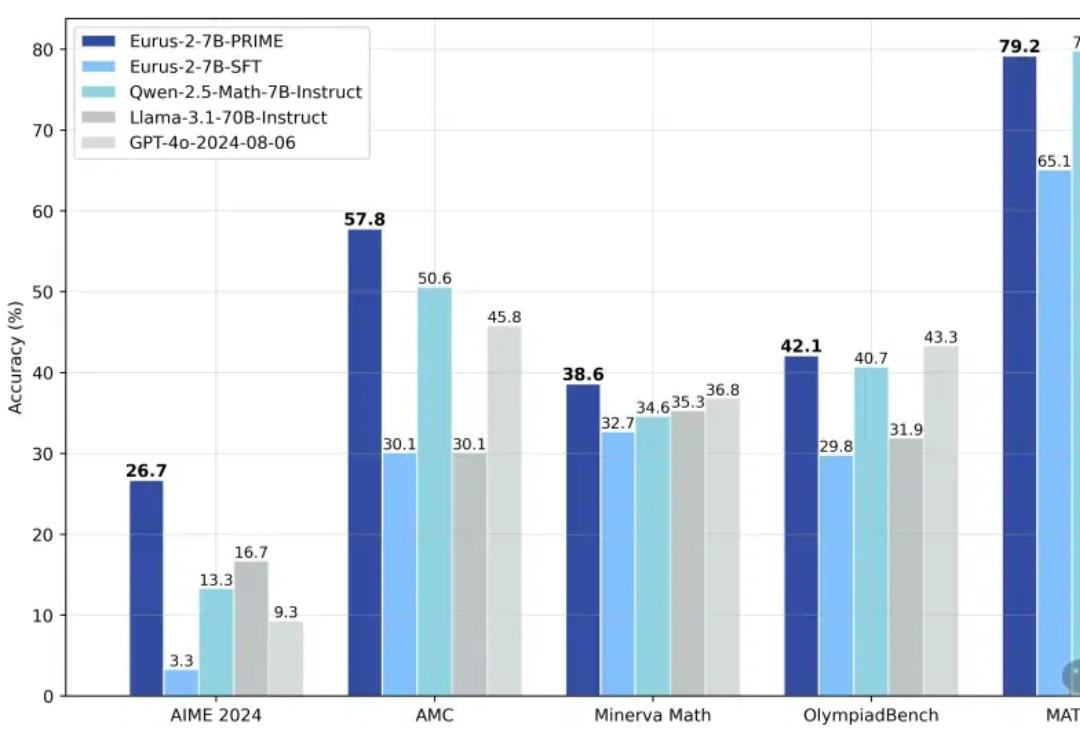
1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。
Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。

亚马逊的 Prime Video 作为 NFL 周四晚橄榄球赛(Thursday Night Football,TNF)的独家版权持有者,正在为第二年的赛事做准备,这家流媒体服务公司希望通过一系列人工智能驱动的新功能,为球迷带来更强的观看体验。