实测Qwen3.6-27B:4分钟做了个跑酷游戏,验证码识别正确率超90%
实测Qwen3.6-27B:4分钟做了个跑酷游戏,验证码识别正确率超90%Qwen3.6系列全员集结完毕。
来自主题: AI产品测评
7482 点击 2026-04-24 10:12
 搜索
搜索
Qwen3.6系列全员集结完毕。
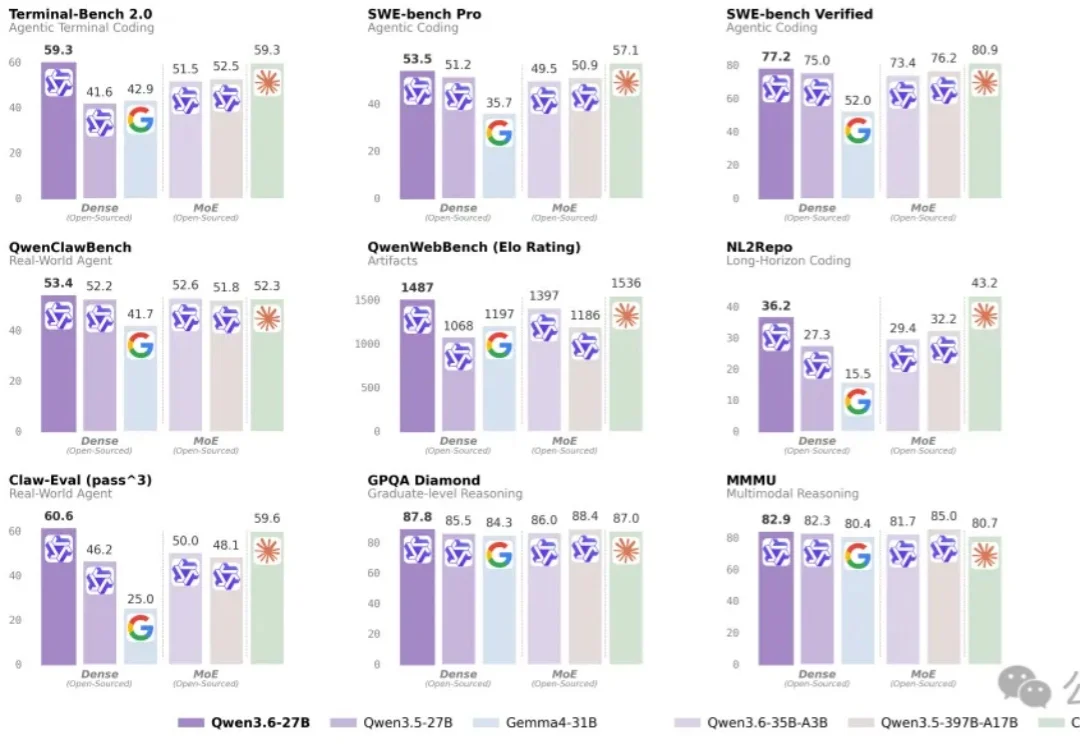
我秒了我自己??

阿里前几天开源的Qwen3.6-35B-A3B,让这次讨论不再只是一次普通的新旧模型对比。它一边要面对谷歌Gemma4-26B-A4B的外部竞争,一边又必须回答一个更麻烦的问题:相较于 Qwen3.5-35B-A3B,它到底是升级,还是修补?更现实的是,很多人现在真正跑着的,其实是Qwen3.5-27B,那么这条新的35B-A3B路线,到底值不值得迁过去。
今天,阿里发布了其下一代旗舰模型的早期预览版:Qwen3.6-Max-Preview。在第三方评测榜单Artificial Analysis的智能指数排名中,Qwen3.6-Max-Preview的得分为52分,小幅超过GLM-5.1、MiniMax-M2.7,成为这一榜单上得分最高的国产模型。

3B激活参数,视觉能力直逼Claude Sonnet 4.5。

全球最强编程模型,中国造。
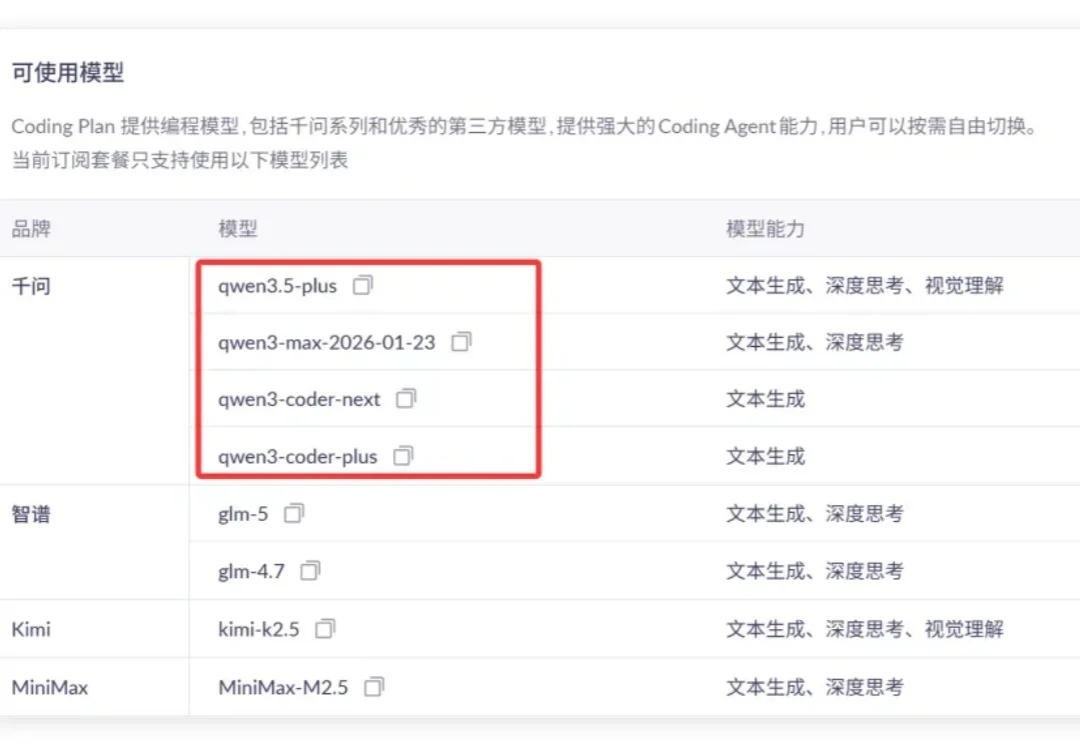
昨天我发现 Qwen3.6“倒反天罡”。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。

Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?

2026 年,阿联酋哈利法大学的邹航博士和他所在的团队,做出了全世界第一个射频大模型,名字叫 RF GPT。这个模型能直接看懂无线信号,就像 GPT 4o 能看懂图片、Qwen2 Audio 能听懂声音一样。你把无线信号扔给它,它不仅能告诉你这里面有几种信号、分别是什么技术,还能分析出有没有信号在打架、哪个是 5G 哪个是蓝牙、甚至能数出来 WiFi 网络里有多少个用户同时在用。