又快又省?仅5%参数、训练快4倍!ArcFlow用「非线性」魔法实现FLUX/Qwen推理40倍加速
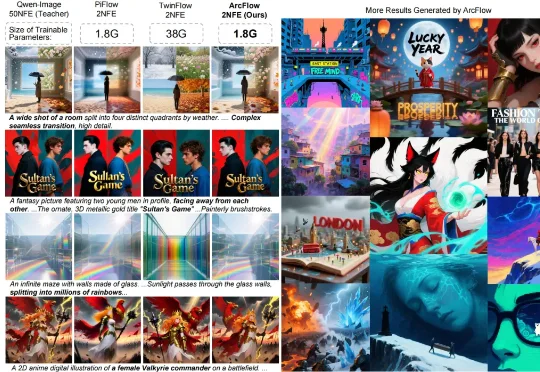
又快又省?仅5%参数、训练快4倍!ArcFlow用「非线性」魔法实现FLUX/Qwen推理40倍加速复旦大学与微软亚洲研究院带来的 ArcFlow 给出了答案:如果路是弯的,那就学会 “漂移”,而不是把路修直。在扩散模型中,教师模型(Pre-trained Teacher)的生成过程本质上是在高维空间中求解微分方程并进行多步积分。由于图像流形的复杂性,教师模型原本的采样轨迹通常是一条蜿蜒的曲线,其切线方向(即速度场)随时间步不断变化。
来自主题: AI技术研报
8434 点击 2026-02-25 14:15