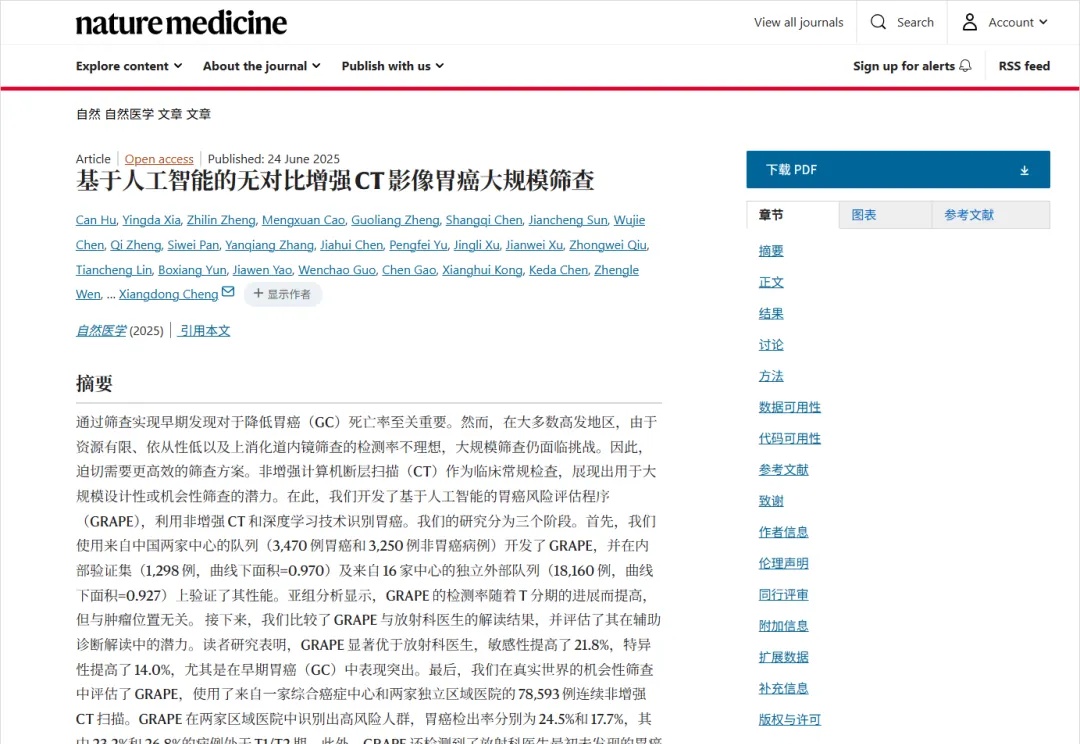
斯坦福Arc Tahoe-100M虚拟细胞团队专访:AI制药的壁垒不是"模型"?而是高质量、亿级规模的数据集
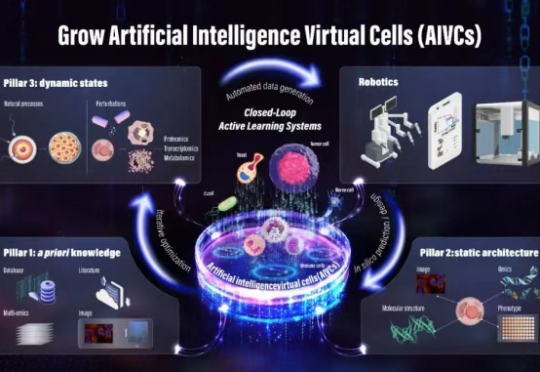
斯坦福Arc Tahoe-100M虚拟细胞团队专访:AI制药的壁垒不是"模型"?而是高质量、亿级规模的数据集Vevo Therapeutics(现为Tahoe)与Arc研究所,两家分别在生物技术商业转化和非营利性基础研究领域领先的机构,于2025年2月联合发布了一项里程碑式的成果:全球最大的单细胞药物扰动数据集Tahoe-100M。
来自主题: AI资讯
9746 点击 2025-07-14 12:57