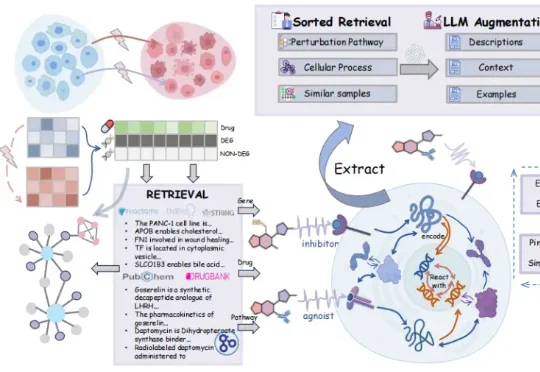
AI虚拟细胞面世,无需等待实验,可预警药物疗效与机制
AI虚拟细胞面世,无需等待实验,可预警药物疗效与机制有了 AI,科学研究是否有一天可以摆脱对湿实验的高度依赖,通过在计算机中构建“虚拟细胞”,来模拟和理解新药可能产生的生物效应?如今,这一愿景正被逐步实现。由上海交通大学郑双佳教授及其研究团队打造的 V
来自主题: AI资讯
8738 点击 2026-01-11 10:10
 搜索
搜索
有了 AI,科学研究是否有一天可以摆脱对湿实验的高度依赖,通过在计算机中构建“虚拟细胞”,来模拟和理解新药可能产生的生物效应?如今,这一愿景正被逐步实现。由上海交通大学郑双佳教授及其研究团队打造的 V

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。
当 OpenAI 前 CTO Mira Murati 创立的 Thinking Machines Lab (TML) 用 Tinker 创新性的将大模型训练抽象成 forward backward,optimizer step 等⼀系列基本原语,分离了算法设计等部分与分布式训练基础设施关联,

她是当代人工智能界最具象征意义的女性科学家之一。提到人工智能领域,李飞飞(Fei-Fei Li)无疑是最醒目的那一个。1976年出生的她,早年在美求学,1999年以物理学荣誉学士毕业于普林斯顿大学,随后在加州理工学院获得电气工程博士学位。
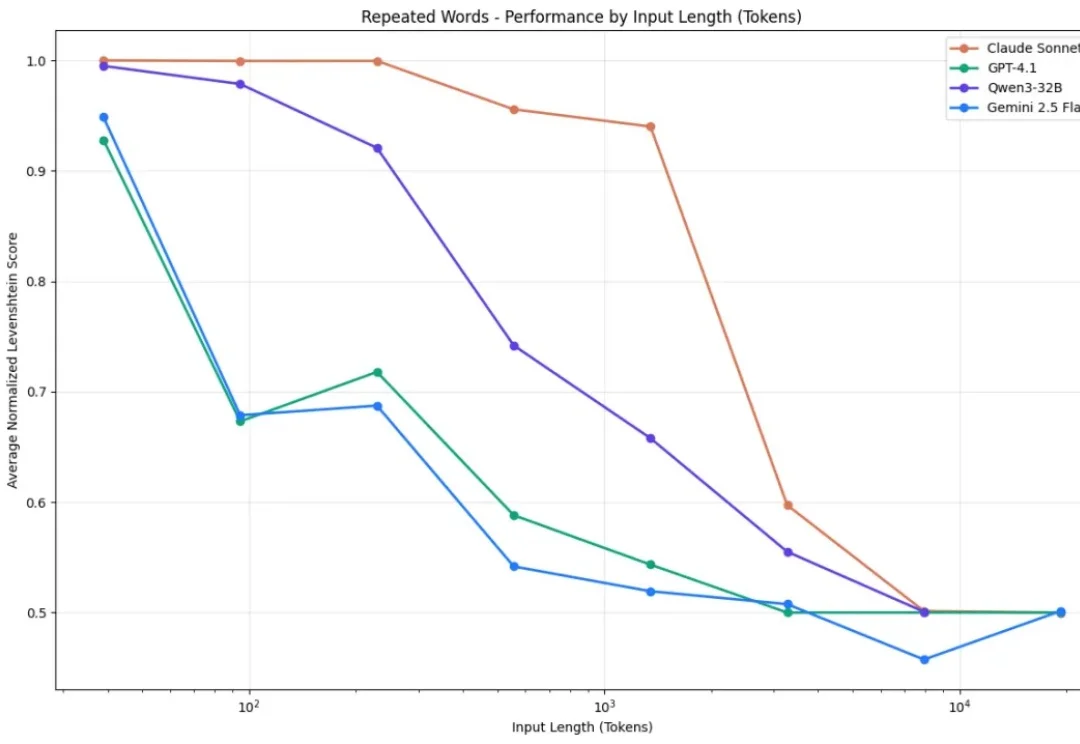
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。
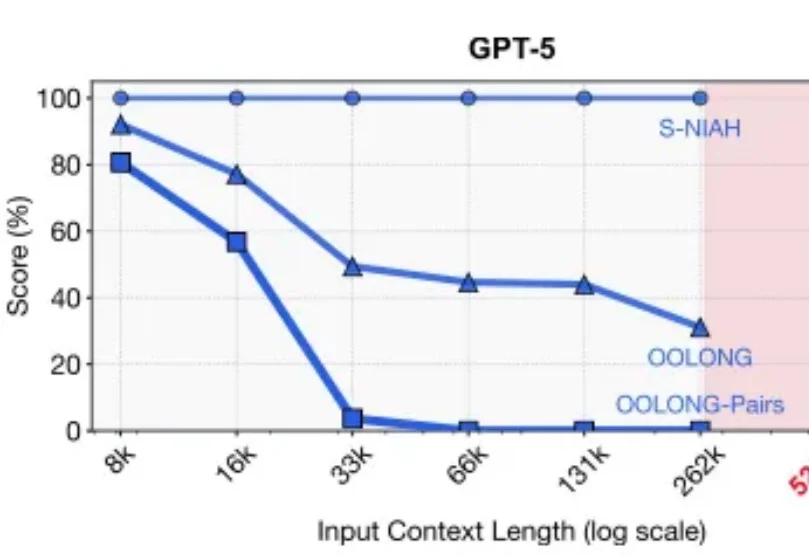
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。

数字孪生行业首家年收入超2.50亿港元的公司。

当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
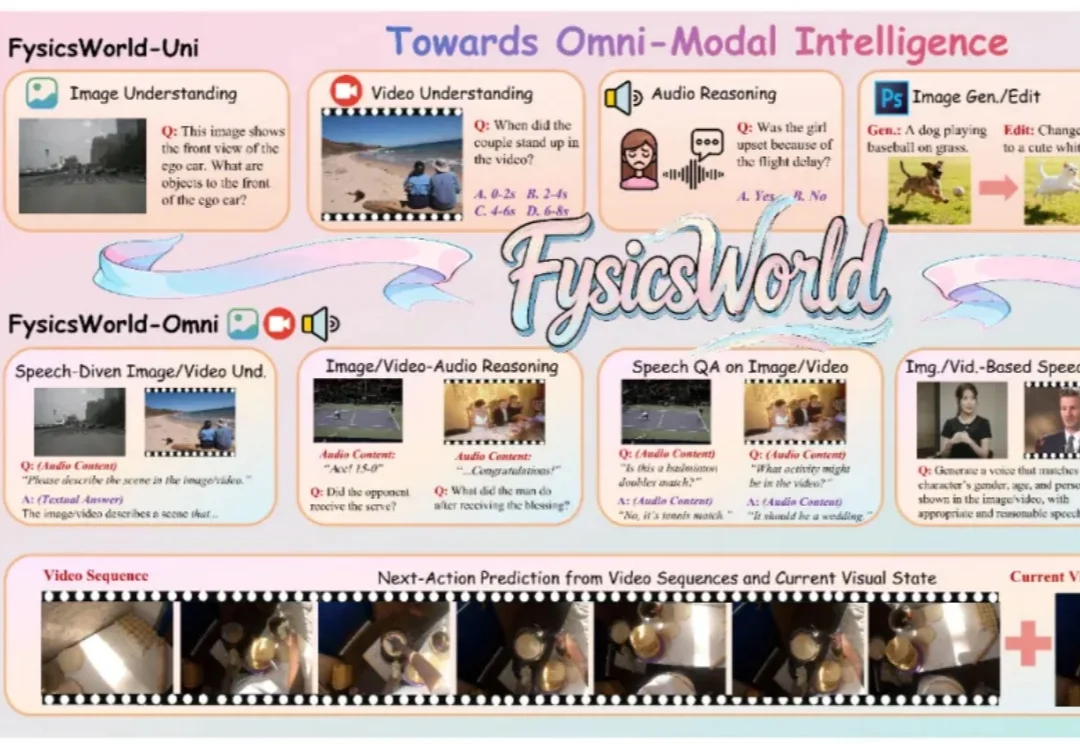
近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。