RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
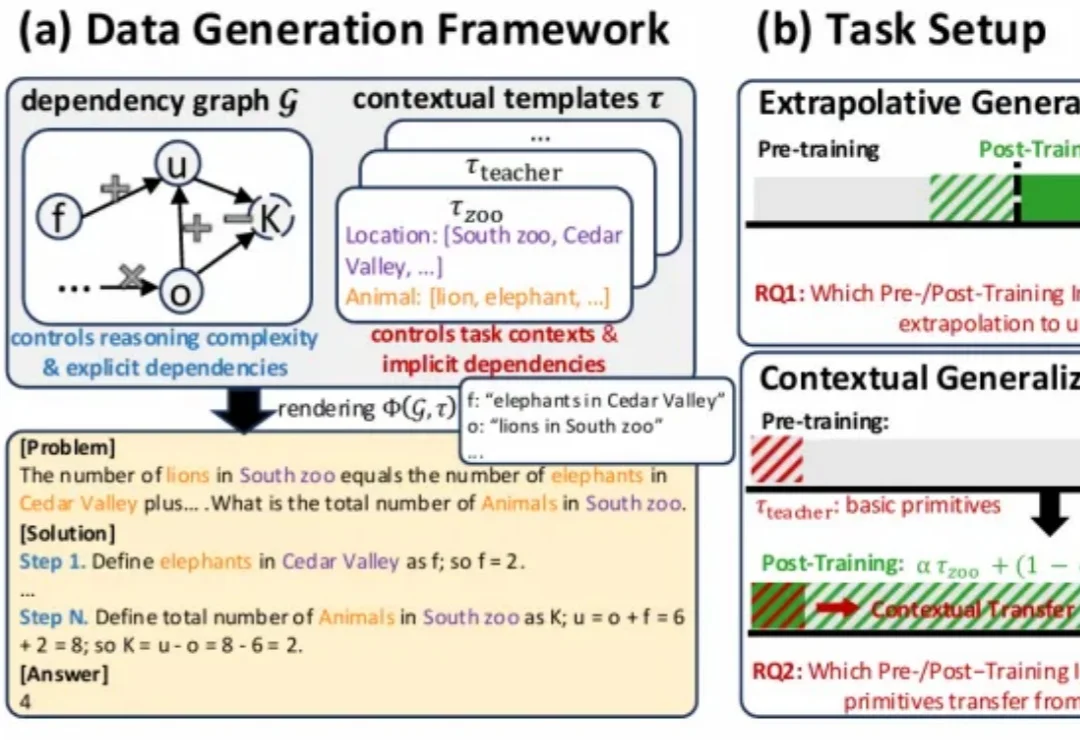
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。
来自主题: AI技术研报
9419 点击 2025-12-16 09:17
 搜索
搜索
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:

世界模型赛道,又有老面孔新鲜入局! 就在刚刚,Runway发布旗下首个通用世界模型GWM-1。 不止于此,还打包发布了一系列世界模型变体:模拟真实环境的GWM Worlds;

昨天,苹果一篇新论文在 arXiv 上公开然后又匆匆撤稿。原因不明。论文中,苹果揭示了他们开发的一个基于 TPU 的可扩展 RL 框架 RLAX。是的,你没有看错,不是 GPU,也不是苹果自家的 M 系列芯片,而是谷歌的 TPU!还不止如此,这篇论文的研究中还用到了亚马逊的云和中国的 Qwen 模型。

主攻 AI 视频与多媒体生成技术的独角兽 Runway 也来了一波大的:一口气来了 5 个「激动人心的宣布」。这一波更新之猛,甚至让人觉得他们是不是把过去半年的大招一次性全放了出来。Runway 这一波发布,不仅刷新了视频生成的各项指标,更重要的是,他们正式对外展示了其在通用世界模型(General World Models/GWM)上的野心。

提起马卡龙,你会想到什么?是橱窗里的精致甜点,一种“少女心”的味觉象征?还是代表了温柔优雅的时尚配色?当一个AI产品也被命名为“马卡龙”,这份联想便悄然发生了偏移:从舌尖的甜,转向科技的未知,却又奇妙地保留了那一份色彩与气质。

最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
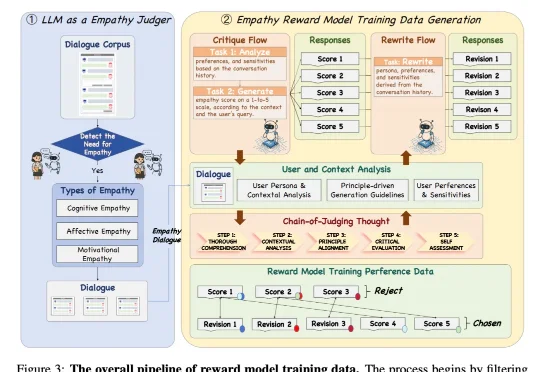
近日,来自 NatureSelect(自然选择)的研究团队 Team Echo 发布了首个情感大模型 Echo-N1,提出了一套全新的「情感模型训练方法」,成功将 RL 用在了不可验证的主观情感领域。仅 32B 参数的 Echo-N1,在多轮情感陪伴任务中胜率(Success Rate)达到 46.7%。作为对比,
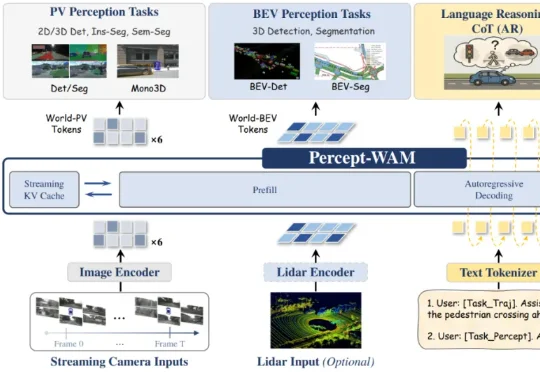
近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。

目标物理世界的“ChatGPT时刻”。