# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
但华为与香港科大的最新研究发现了一个出人意料的现象:在多模态视觉语言模型(VLM)中,这对组合难以实现协同增益,甚至有时会互相拖后腿。

推动这项研究的一个关键见解是认识到多模态推理评测与纯语言评测存在微妙差异。虽然文本推理任务通常侧重于逻辑要求高的问题,但多模态评测通常包含简单基于感知的问题和复杂的认知推理挑战。作者假设,这种异质性是 Long-CoT SFT 和 RL 在多模态设置中表现出不同现象的核心原因。
为探索各种后训练技术如何影响不同类型问题性能,作者们引入了一个简单有效的难度分类方法,并基于此构建了难度层级细化后的多模态推理榜单数据集(包括新的 MathVision、MathVerse、MathVista、MMMU val 和 MMStar val)。该方法根据基线模型 Qwen2.5-VL-Instruct-7B 在五个数据集的每个问题上 16 次独立运行的成功率,将题目分为五个级别(L1-L5),分别代表从简单到困难:
数据、模型地址:https://github.com/JierunChen/SFT-RL-SynergyDilemma
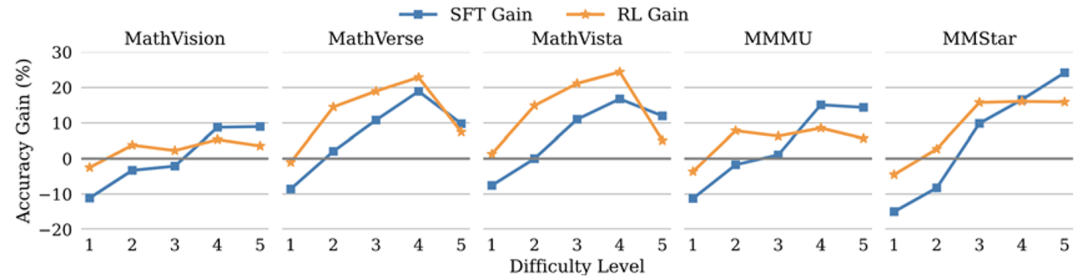

长思维链 SFT 引导模型反复演算,专攻难题
长思维链 SFT 就像给模型配备了 「超级草稿本」,通过少量带反思验证等思考模式的推理样本训练,让模型学会层层拆解复杂问题:
RL 强化模型整体性能,能力均衡不偏科
强化学习则像给模型装上 「精准导航」,通过奖励机制引导模型输出高质量答案:
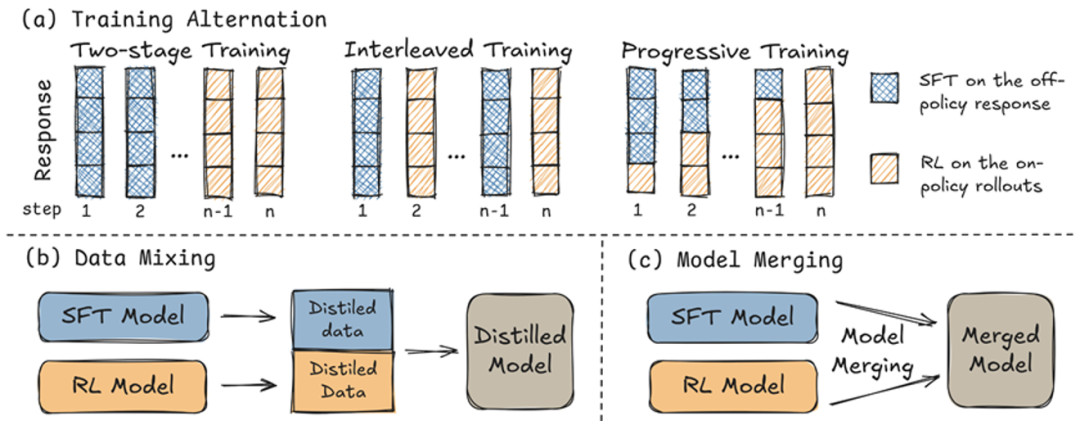
协同困境:五种组合策略全失效
既然 SFT 强于难题、RL 长于均衡,研究团队尝试了五种组合方案,结果令人意外,所有方法都没能实现 「1+1>2」 的效果:
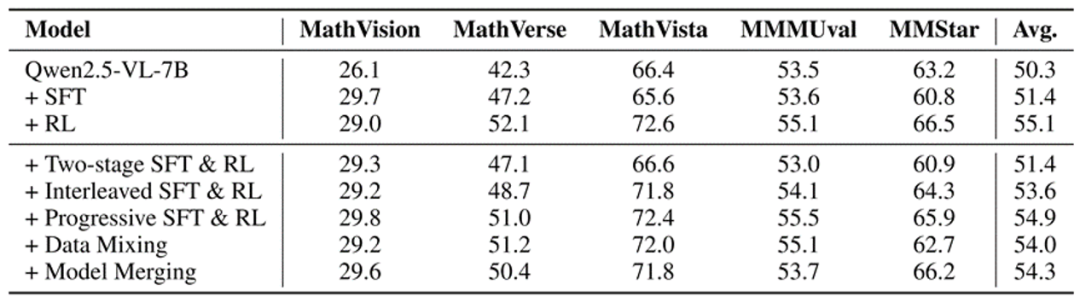
其中两阶段、交替式和渐进式的混合训练曲线如图所示
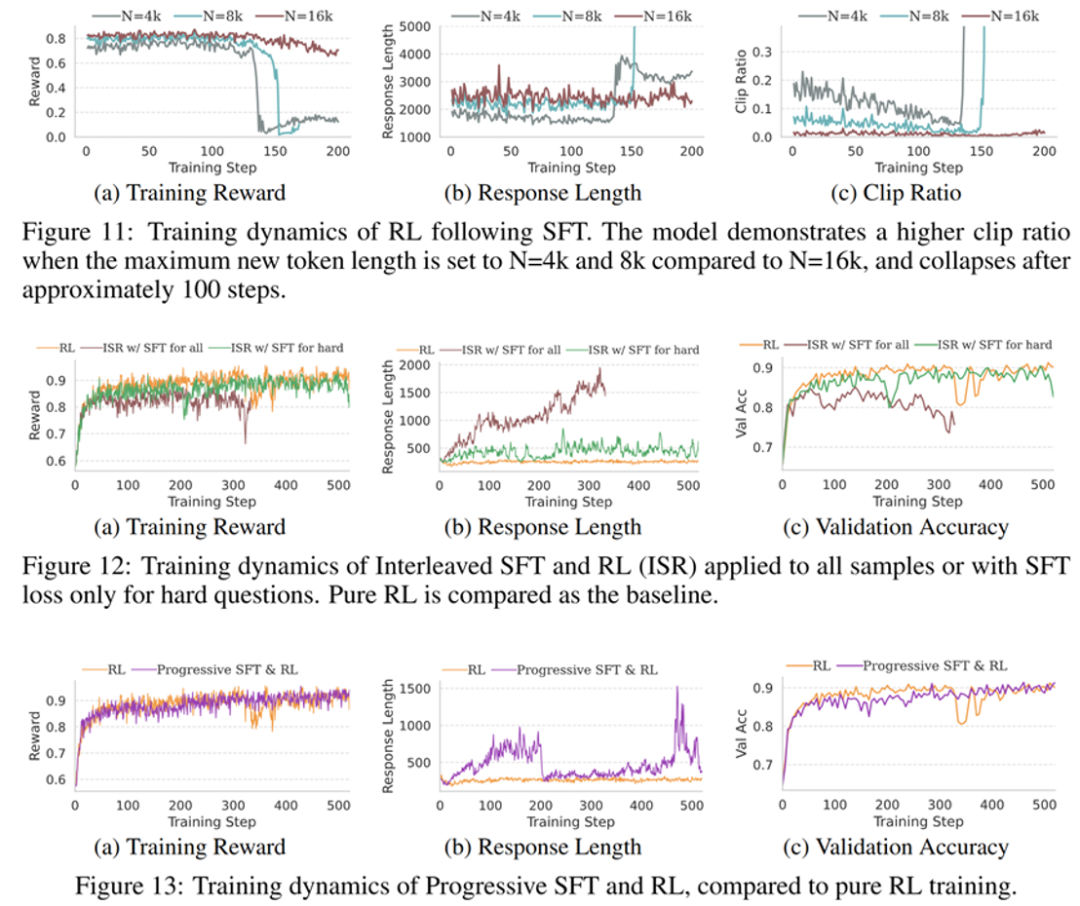
其他实验发现
未来方向:让模型学会 「见题下菜碟」
1. 自适应推理:长思维链 SFT 带来的慢思考和 RL 强化的快思考两种回答范式难以兼容,VLM 的题目异质性更是放大了这种冲突,未来研究应考虑如何有效实现模型自适应推理,对简单题给出简洁回答,对难题采用深度推理。
2. 构建模型亲和的训练数据:在此项研究中,长思维链数据是从外部模型蒸馏而来,可能和基线模型存在亲和性不足的风险。为避免损害模型基础能力,应考虑采用其他方式如提示词工程自蒸馏构建训练数据。
3. 分层评估体系:将榜单分为不同难度题目,有助于差异化、针对性地评测和优化模型。
文章来自于微信公众号“机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
