AGI真方向?谷歌证明:智能体在自研世界模型,世界模型is all You Need
AGI真方向?谷歌证明:智能体在自研世界模型,世界模型is all You Need越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。
来自主题: AI技术研报
8442 点击 2025-06-14 13:22
 搜索
搜索
越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,

第一财经「新皮层」独家获悉,MiniMax即将推出文本推理模型,并将开源。半个月前,MiniMax刚刚发布和开源了视觉推理模型Orsta(One RL to See Them All)。MiniMax今年3月做出产品线调整,将旗下现有产品「海螺AI」更名为「MiniMax」,与公司同名,聚焦文本理解和生成;

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

他不是天才,博士毕业0顶会论文,却靠着坚持写技术博客,因RLHF「网红」博客文章一炮而红,逆袭成功、跻身AI核心圈!技术可以迟到,但影响力不能缺席。这一次,是写作改变命运。

AI顶流Claude升级了,程序员看了都沉默:不仅能写代码能力更强了,还能连续干活7小时不出大差错!AGI真要来了?这背后到底发生了什么?现在,还有机会加入AI行业吗?如今做哪些准备,才能在未来立足?

清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!

World Labs 是由著名 AI 专家、斯坦福大学教授李飞飞于 2024 年创办的初创公司,致力于开发具备“空间智能”的下一代 AI 系统。

无监督的熵最小化(EM)方法仅需一条未标注数据和约10步优化,就能显著提升大模型在推理任务上的表现,甚至超越依赖大量数据和复杂奖励机制的强化学习(RL)。EM通过优化模型的预测分布,增强其对正确答案的置信度,为大模型后训练提供了一种更高效简洁的新思路。
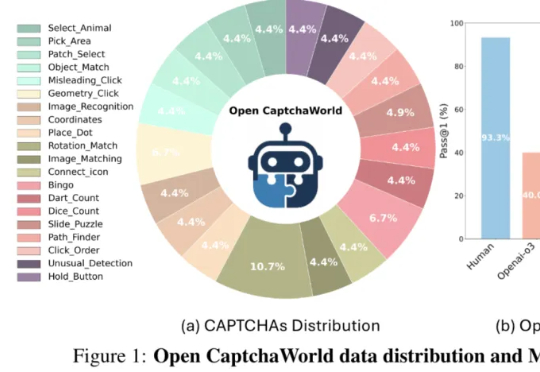
当前最强多模态Agent连验证码都解不了?