
奥尔特曼遭美国政府调查!
奥尔特曼遭美国政府调查!美国众议院监督与政府改革委员会官网显示,该机构于当地时间5月8日向OpenAI联合创始人兼CEO萨姆·奥尔特曼(Sam Altman)发出正式调查函,要求其在5月22日前提供OpenAI全部利益冲突审查文件,并安排首席法务官等高管接受国会简报。此次调查的核心问题是,奥尔特曼是否利用其执掌的OpenAI,为其个人持有股权的外部公司人为抬高估值。
来自主题: AI资讯
8216 点击 2026-05-13 11:29
 搜索
搜索
美国众议院监督与政府改革委员会官网显示,该机构于当地时间5月8日向OpenAI联合创始人兼CEO萨姆·奥尔特曼(Sam Altman)发出正式调查函,要求其在5月22日前提供OpenAI全部利益冲突审查文件,并安排首席法务官等高管接受国会简报。此次调查的核心问题是,奥尔特曼是否利用其执掌的OpenAI,为其个人持有股权的外部公司人为抬高估值。
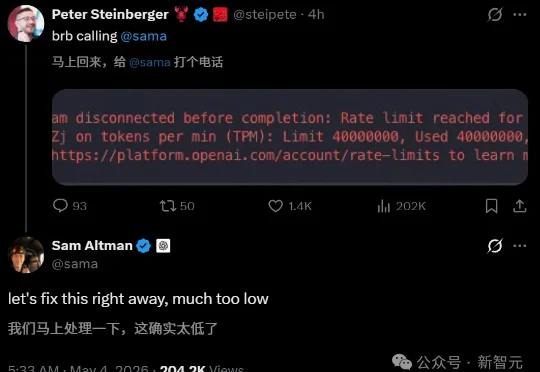
一分钟,4千万token,灰飞烟灭。 「龙虾之父」Peter Steinberger大概没想到,自己会以这种方式上热搜。今年2月他被Sam Altman亲自招入OpenAI,负责「下一代个人代理」的开发。
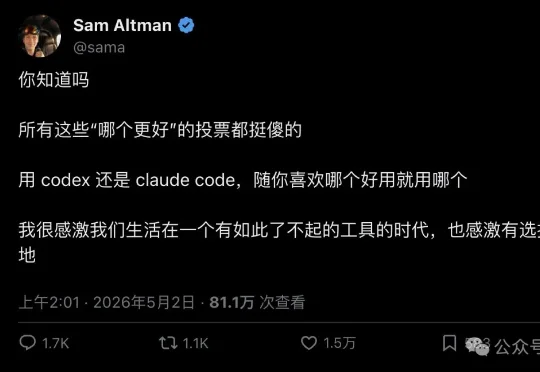
OpenAI CEO 一条推文拿下 80 万浏览、1.5 万点赞,开发者圈最火的"二选一"争论,被当事人自己按下了暂停键。5 月 2 日,Sam Altman 在 X 上发了一条看似随意、实则信息量极大的帖子:

据The Verge等多家外媒报道,今天凌晨,埃隆·马斯克(Elon Musk)与OpenAI CEO萨姆·奥尔特曼(Sam Altman)的世纪庭审在加州奥克兰联邦法院进入开庭陈词阶段。当天,马斯克身穿黑色西装、系黑色领带,出现在联邦法院。马斯克方、OpenAI方与微软方依次发表开庭陈词,随后马斯克作为本案第一证人进行举证。

今天,马斯克起诉OpenAI及其CEO萨姆·奥尔特曼(Sam Altman)、总裁格雷格·布罗克曼(Greg Brockman)一案,在美国加州奥克兰联邦法院正式开庭。

OpenAI CEO Sam Altman 向加拿大小镇 Tumbler Ridge 道歉:公司曾封禁枪击案嫌疑人的 ChatGPT 账号,却未向警方预警。事件造成 8 人死亡,也把 AI 平台的风险识别、执法转介和未成年人监管推到台前。

刚刚,外媒《旧金山标准报》报道,当地时间4月12日凌晨1点40分,OpenAI CEO萨姆·阿尔特曼(Sam Altman)的住所又被袭击,两名嫌疑人从车内向阿尔特曼的住所开枪,无人受伤。

2026 年 1 月,Twitch 的一场 Subathon(订阅马拉松直播)中,AITuber Neuro-Sama(账号名:Vedal987)以约 16 万活跃订阅数一度登顶 Twitch 订阅榜,且拉开第二名、知名游戏主播 Jynxzi 的订阅数据一倍有余。
OpenAI 加快了迈向下一 AI 阶段的进程。

2026 年 4 月 2 日,科技播客 Mostly Human 主持人 Laurie Segall 发布了一期重磅对话——与 OpenAI CEO Sam Altman 的深度对谈。这是 Altman 自今年 2 月五角大楼协议风波以来的首次公开长访谈,也恰逢 OpenAI 以 8520 亿美元估值完成 1220 亿美元融资、关停 Sora、高管层剧烈变动的多事之秋。