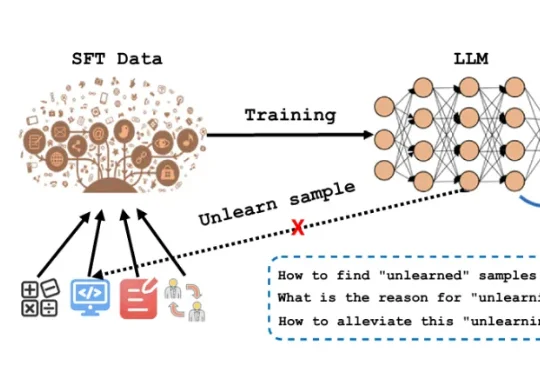
Loss收敛不代表学会:腾讯混元ACL 2026拆解SFT训练中15.3%的“假学会”样本
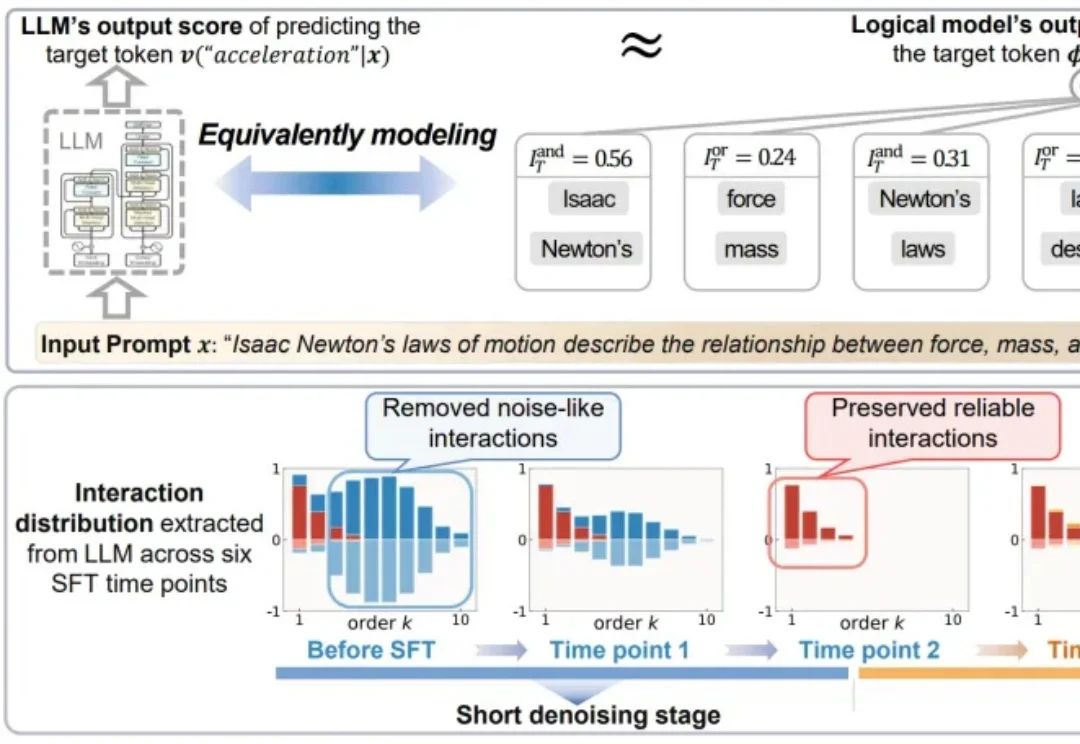
Loss收敛不代表学会:腾讯混元ACL 2026拆解SFT训练中15.3%的“假学会”样本SFT是LLM从“通才”变成“专才”的关键步骤。业界默认做法是:准备标注数据(QA对、指令-回复对等)在基座模型上跑SFT训练。看loss曲线收敛了→认为训练完成。但问题在于:loss是全局平均,掩盖了样本间的差异。loss收敛只代表“大部分样本学会了”——那些始终学不会的样本被淹没了。
来自主题: AI技术研报
8388 点击 2026-07-26 11:25