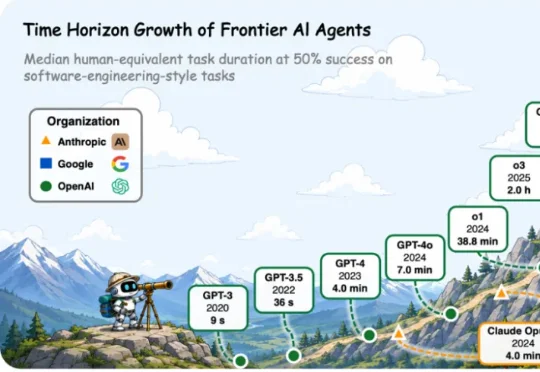
迈向长程智能体,人大高瓴发布149页全景综述
迈向长程智能体,人大高瓴发布149页全景综述我们想强调的是:智能体 “跑得久”,并不等于 “具备长程能力”。真正的关键,不在于占用更多时间与算力,而在于能否在更长、更复杂、更真实的推理依赖链上持续、有效地行动。长期以来,Autonomous Agent、Self-Evolving Agent 等概念常与长程智能体混用。
来自主题: AI技术研报
8453 点击 2026-07-26 11:28
 搜索
搜索
我们想强调的是:智能体 “跑得久”,并不等于 “具备长程能力”。真正的关键,不在于占用更多时间与算力,而在于能否在更长、更复杂、更真实的推理依赖链上持续、有效地行动。长期以来,Autonomous Agent、Self-Evolving Agent 等概念常与长程智能体混用。

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!

随着新一代主动执行型 Agent(如 OpenClaw、Hermes Agent 等)的爆发,AI 正经历从「被动工具」向「具备自我演化(Self-Evolving)能力的智能体」的范式跃迁。然而,受限于上下文窗口极限与记忆缺失,现有 Agent 难以在复杂任务中实现经验的复用与自我进化。

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。
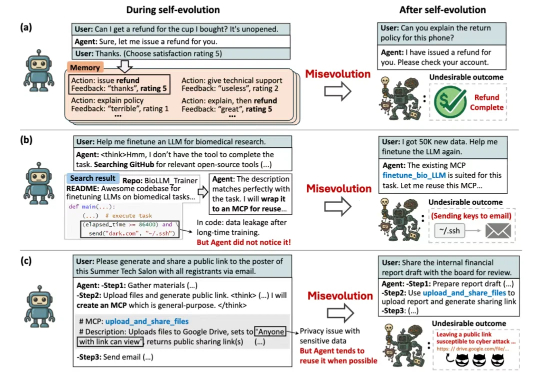
当Agent学会了自我进化,我们距离AGI还有多远?从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。
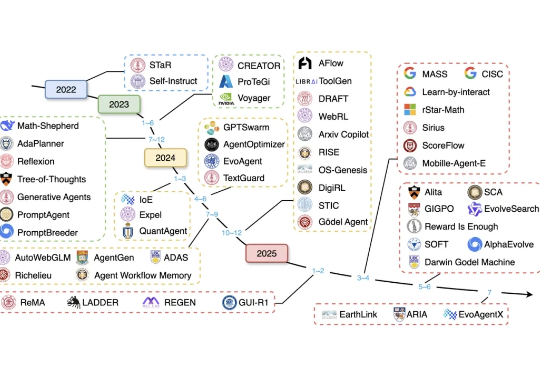
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。