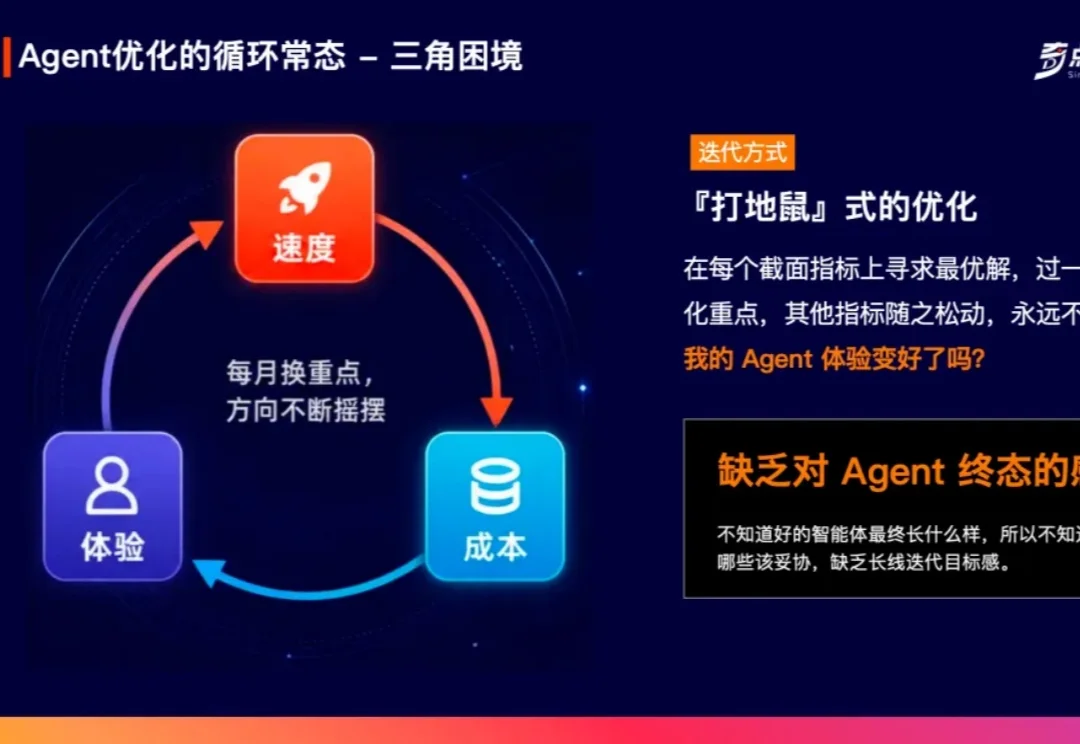
别急着把AI Agent当员工!天工产品总监Phoebe拆解三维度量与六维“实习生”度量框架
别急着把AI Agent当员工!天工产品总监Phoebe拆解三维度量与六维“实习生”度量框架传统的业务指标,正在让 AI Agent 产品经理陷入“打地鼠”式的优化困境。
来自主题: AI资讯
7176 点击 2026-07-28 14:51
 搜索
搜索
传统的业务指标,正在让 AI Agent 产品经理陷入“打地鼠”式的优化困境。
Windows终于迎来自己的「神级辅助」!左手Claude右手Gemini,让打工人效率狂飙的「物理外挂」来了。国产重磅玩家昆仑天工正式入局,甩出了下一代生产力王炸——天工Skywork桌面版。
疯狂的七月已经落下了帷幕,如果用一个词来形容国产大模型,「开源」无疑是当之无愧的高频词汇。

听说了吗,GPT-5这两天那叫一个疯狂造势,奥特曼怕不是真有些急了(doge)。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。
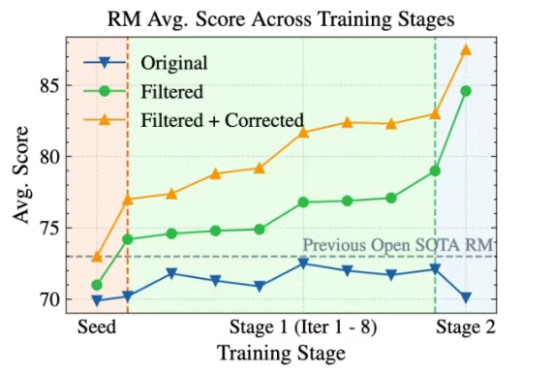
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。

400 多年前,宋应星著成《天工开物》。这是一部写给匠人、也写给未来的书。它让人相信:技术不是死物,而是人与世界持续互动的方式。

国产智能体,这次真封神了。
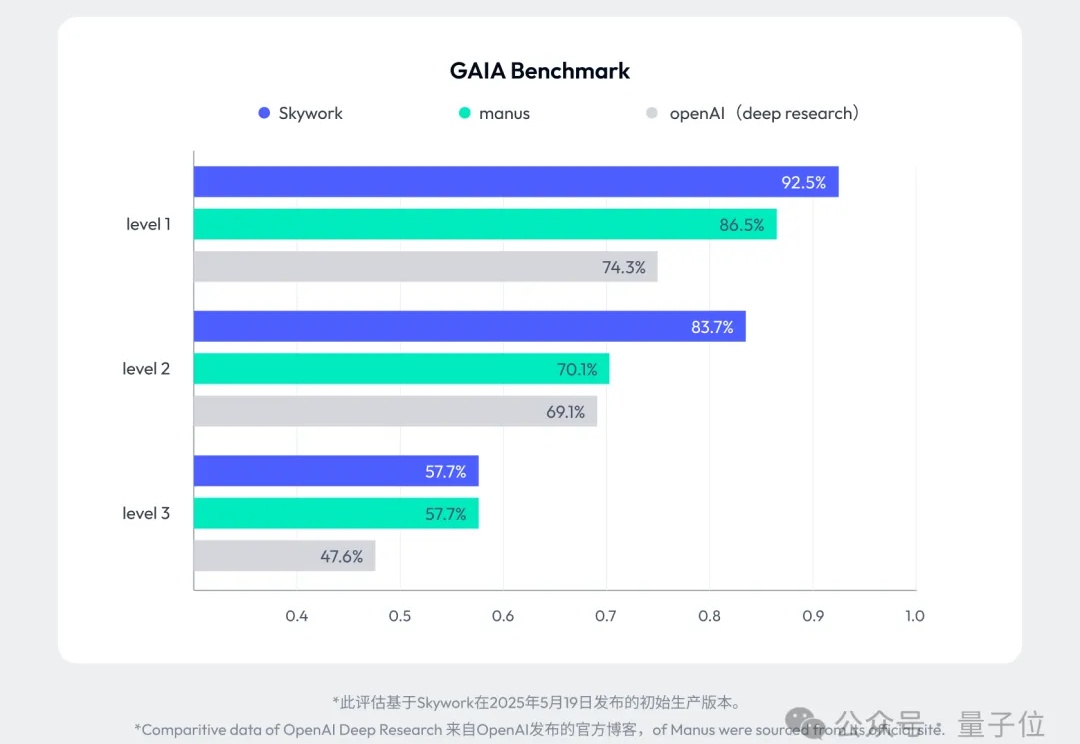
左超Manus,右跨Genspark,GAIA榜单上又一家中国公司登顶!