致敬Kimi K2:基于slime的全流程INT4量化感知RL训练
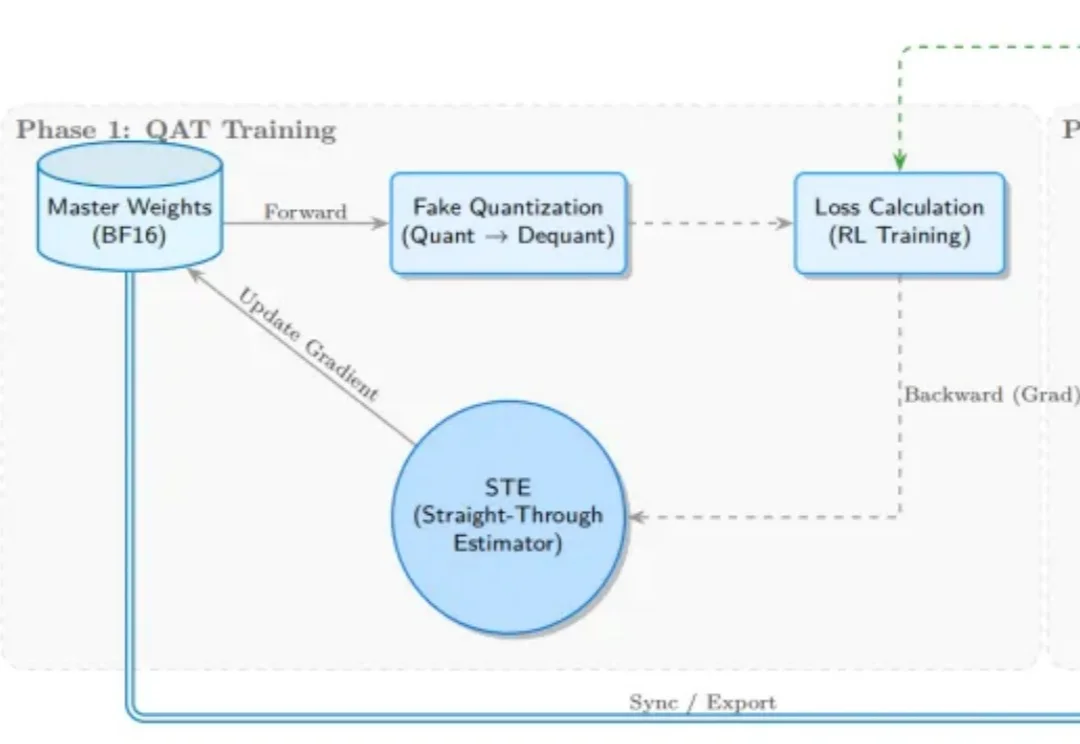
致敬Kimi K2:基于slime的全流程INT4量化感知RL训练受 Kimi K2 团队启发,SGLang RL 团队成功落地了 INT4 量化感知训练(QAT) 流程方案。通过 “训练端伪量化 + 推理端真实量化(W4A16)” 的方案组合,我们实现了媲美 BF16 全精度训练的稳定性与训推一致性,
来自主题: AI技术研报
7577 点击 2026-02-04 16:32
 搜索
搜索
受 Kimi K2 团队启发,SGLang RL 团队成功落地了 INT4 量化感知训练(QAT) 流程方案。通过 “训练端伪量化 + 推理端真实量化(W4A16)” 的方案组合,我们实现了媲美 BF16 全精度训练的稳定性与训推一致性,
真是越到年底,越是神仙打架。

继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。
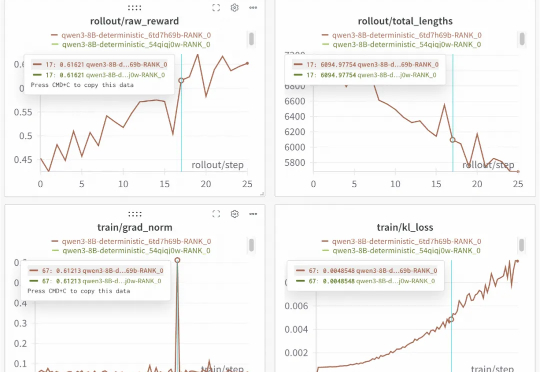
开源框架实现100%可复现的稳定RL训练!下图是基于Qwen3-8B进行的重复实验。两次运行,一条曲线,实现了结果的完美重合,为需要高精度复现的实验场景提供了可靠保障。这就是SGLang团队联合slime团队的最新开源成果。