
101亿!AI Infra独角兽Baseten拿下巨额融资
101亿!AI Infra独角兽Baseten拿下巨额融资客户包括Cursor、Mercor、Lovable、Notion,营收同比增长约20倍。
来自主题: AI资讯
9825 点击 2026-06-24 10:31
 搜索
搜索
客户包括Cursor、Mercor、Lovable、Notion,营收同比增长约20倍。

6 月 23 日,腾讯云发布全新边缘 Web 与 AI Agent 托管平台 Tencent Cloud EdgeOne Makers(以下简称Makers),进一步强化面向Agent时代的 AI 全链路布局。

2020年,吴迪读研一,张启煊念大三,他们跟同为上海科技大学学生的张龙文、曾初啸一起创办了影眸科技。公司早期做过一系列有关3D与生成的探索——做过穹顶光场扫描,做过二次元APP,做过数字人,踩过元宇宙的尾巴,也经历过几乎没有现金流的至暗时刻。
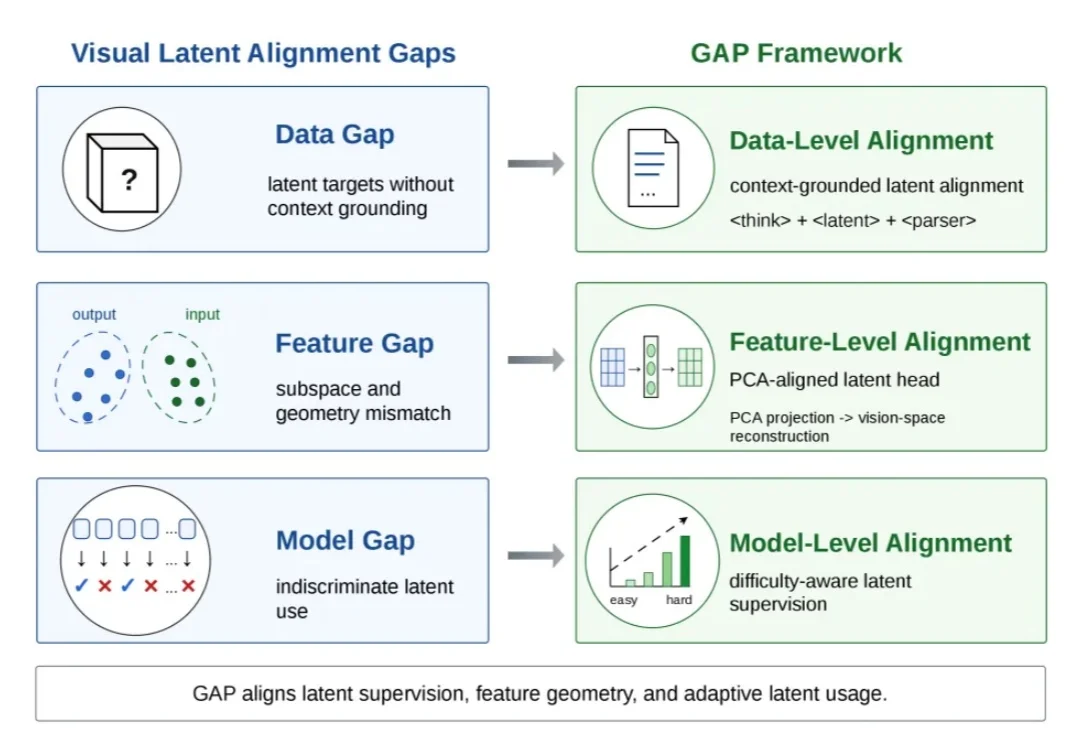
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。

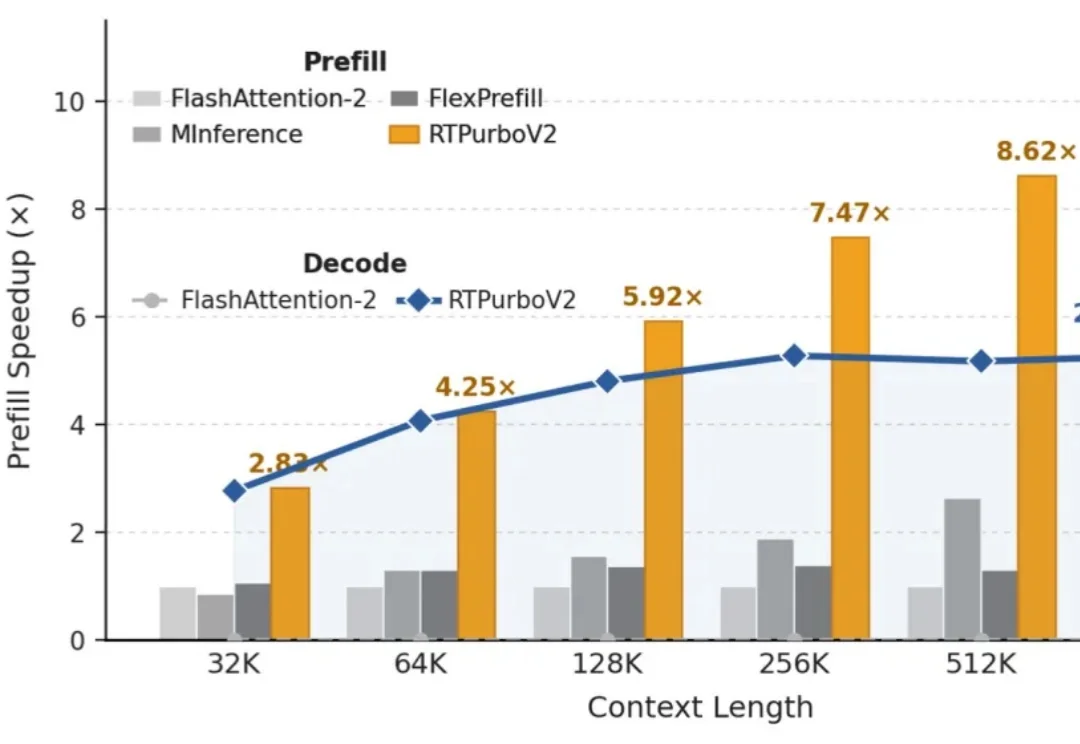
我们在上周五开源了 MiniMax M3 模型权重,同步发布了 MSA(MiniMax Sparse Attention)技术论文。MSA 的架构设计让 M3 在长上下文下的计算成本大幅降低,论文中完整披露了架构与工程实现细节。
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。
“Full Attention 正在被遗忘”

2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。