
独家|蓝驰高瓴下注硅碳互联黑马SiClink,脑机接口从"读懂大脑"走向"重建感知"
独家|蓝驰高瓴下注硅碳互联黑马SiClink,脑机接口从"读懂大脑"走向"重建感知"Z Potentials独家获悉,侵入式脑机接口创业公司SiClink(曦涟科技)近日连续完成数千万元种子轮和天使轮融资,蓝驰创投、高瓴创投、中科神光联合押注。
来自主题: AI资讯
7497 点击 2026-06-02 11:21
 搜索
搜索
Z Potentials独家获悉,侵入式脑机接口创业公司SiClink(曦涟科技)近日连续完成数千万元种子轮和天使轮融资,蓝驰创投、高瓴创投、中科神光联合押注。

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。

腾讯设计领域的WorkBuddy来了。

图片来源:Baseten AI 初创公司 Baseten 近期正与投资者洽谈,计划以 110 亿美元估值(含融资额)募集 10 亿美元资金,据知情人士透露。这将使该公司估值较三个月前公布的上一轮 50

“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )

AI shopping 的热度正在升温。
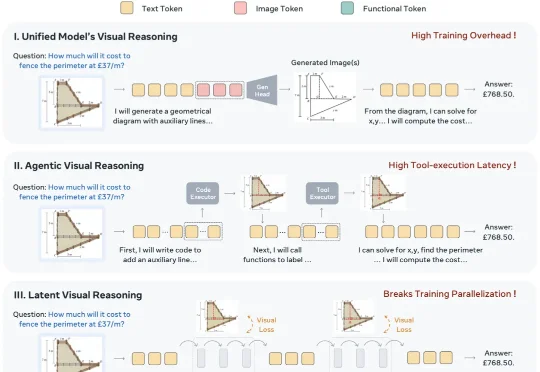
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。
TencentDB Agent Memory 全球正式开源

Z Potentials独家获悉,清华系具身智能公司灵御智能宣布完成天使+轮近亿元人民币融资。本轮融资距离上次融资仅有两个月,由福田资本领投,力合创投、金沙江联合资本、复利多、楹辉创投、华仓资本跟投,老股东英诺基金、天鹰资本持续加注。Maple Pledge枫承资本长期出任公司私募股权融资顾问。