
75个OpenAI打工人,一夜成了亿元富翁
75个OpenAI打工人,一夜成了亿元富翁今日,据《华尔街日报》援引知情人士报道,OpenAI近期在一轮员工股份“要约收购”(Tender Offer)中,允许符合条件的员工每人出售最高价值3000万美元(约合人民币2亿元)的公司股票,这批员工也成为AI浪潮下最早实现大规模财富兑现的群体之一。
来自主题: AI资讯
8004 点击 2026-05-11 20:05
 搜索
搜索
今日,据《华尔街日报》援引知情人士报道,OpenAI近期在一轮员工股份“要约收购”(Tender Offer)中,允许符合条件的员工每人出售最高价值3000万美元(约合人民币2亿元)的公司股票,这批员工也成为AI浪潮下最早实现大规模财富兑现的群体之一。
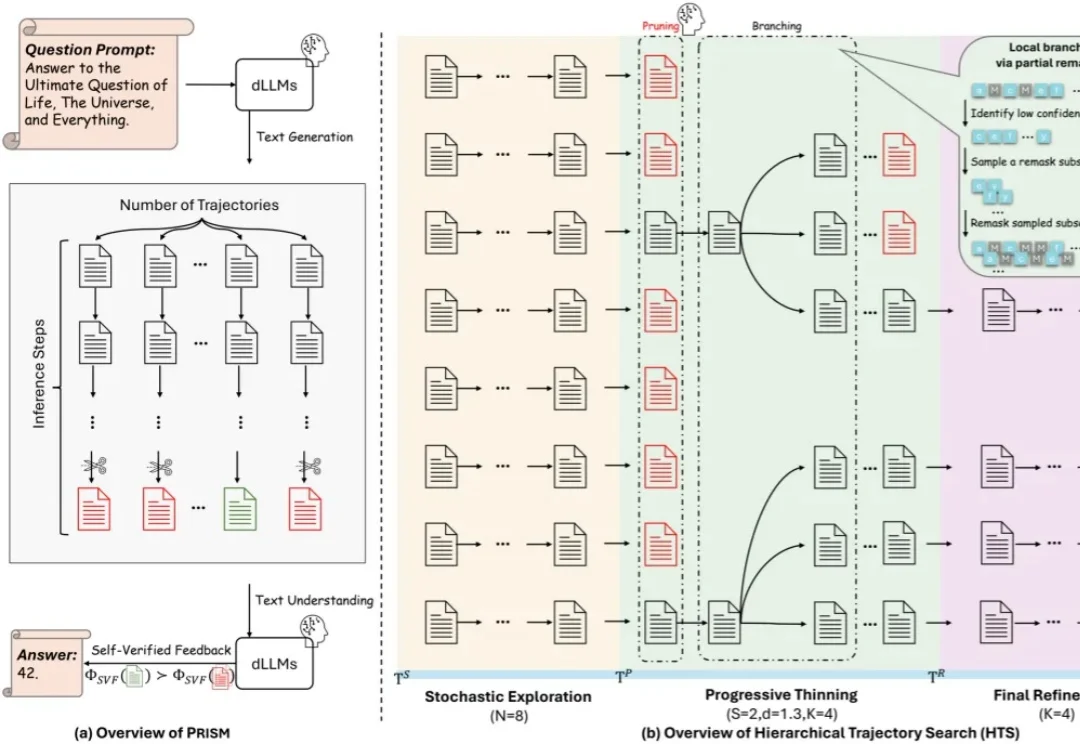
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

旅游是个矛盾的行业。据 WTTC 数据,2024 年全球旅游业贡献 10.9 万亿美元,接近全球 GDP 的 10%,每 10 个工作岗位就有 1 个与之相关。可就是这样一个体量的行业,二十年却没长出过一家真正的旅游公司。
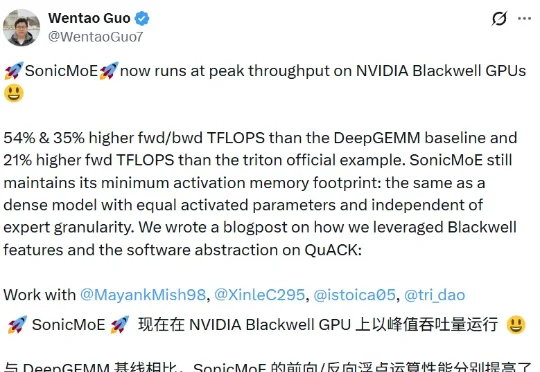
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
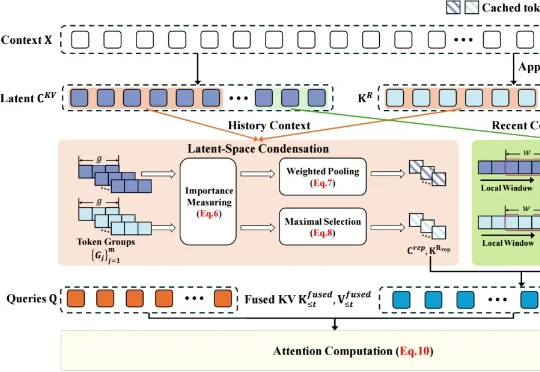
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。
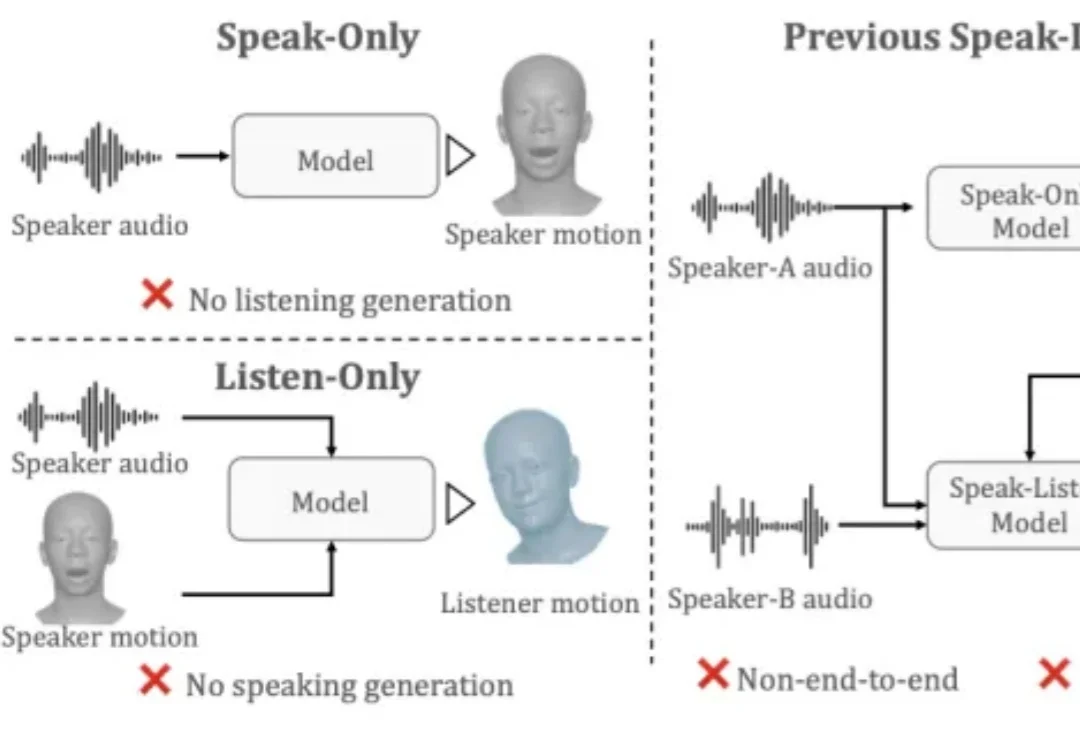
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
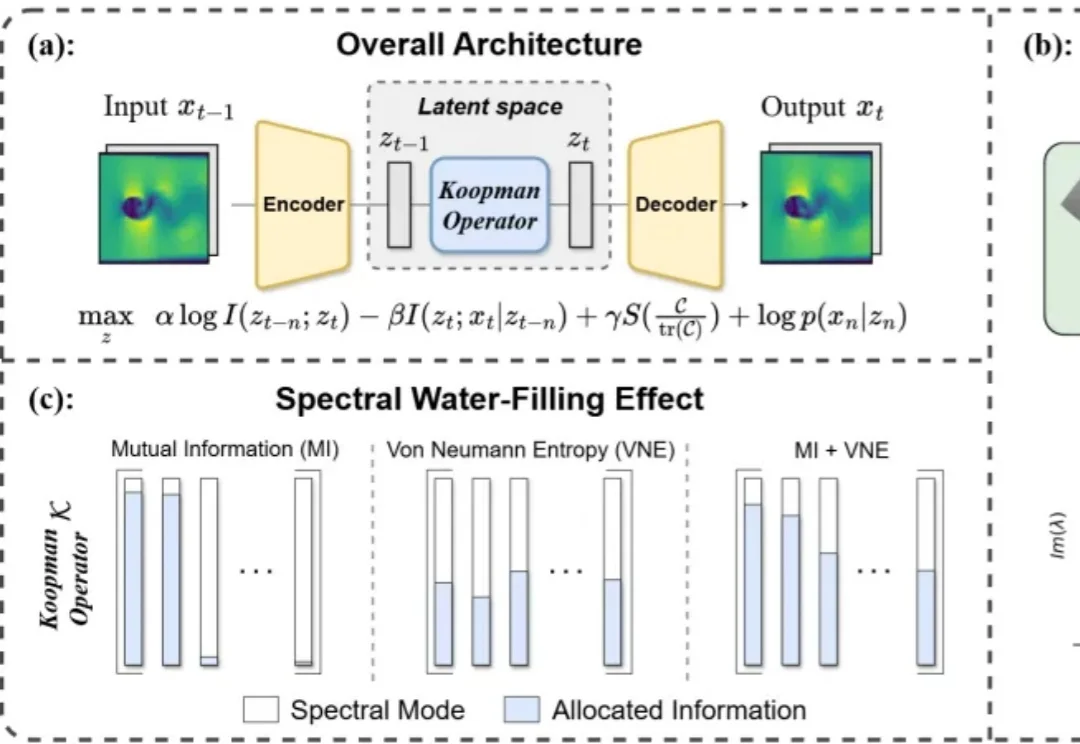
大多数世界模型工作默认:只要学到一个好的 latent dynamics,问题就解决了。 但这个假设本身是可疑的——什么样的信息,才足以支撑一个可预测、可传播的动力学? 本文从信息论出发,重新审视这一前提。
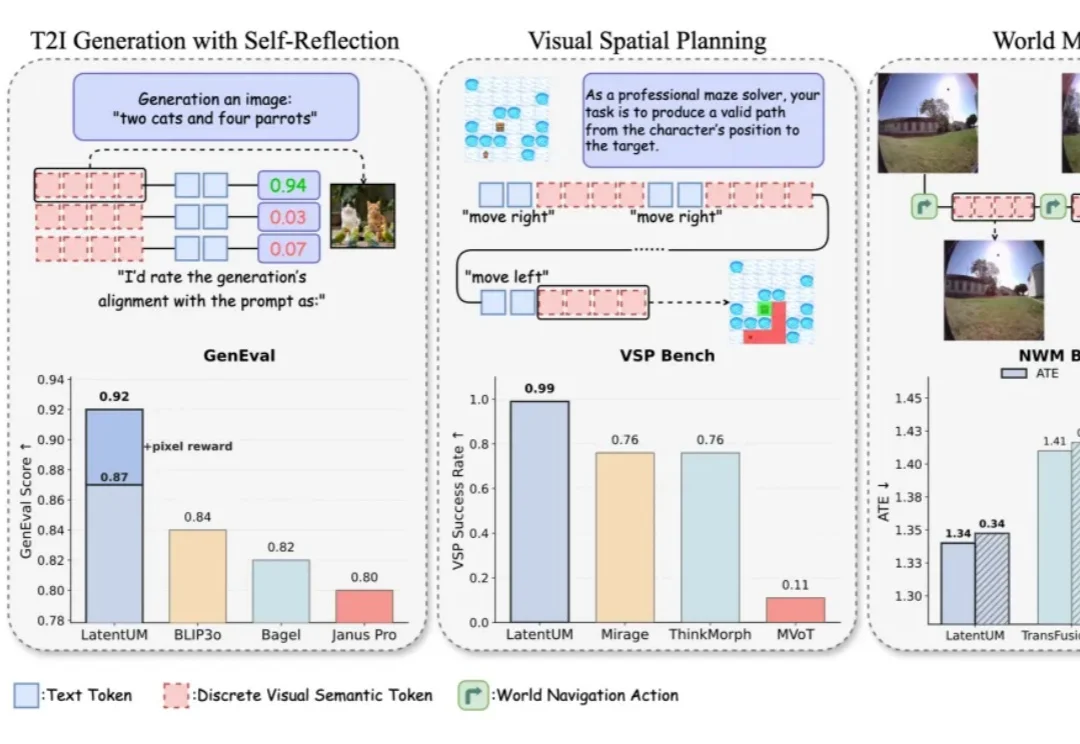
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。