
3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产
3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
来自主题: AI技术研报
10470 点击 2026-06-18 15:30
 搜索
搜索
最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
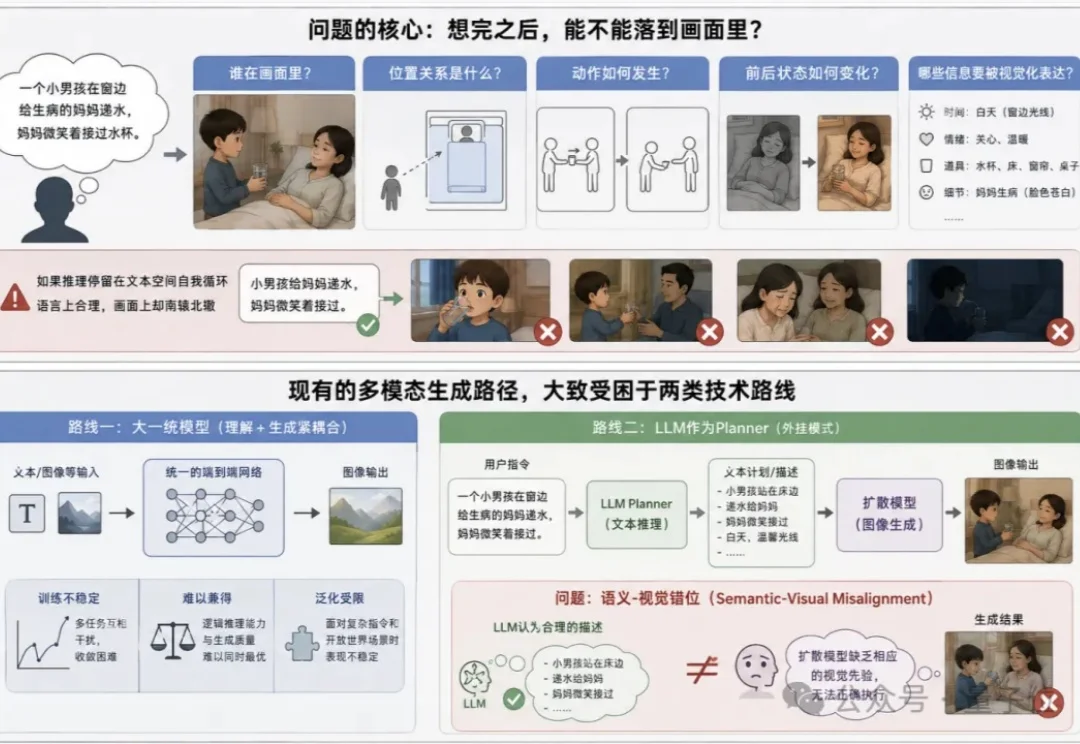
当下视觉生成正陷入一个能力错位困境—— 扩散模型的像素画质已接近完美,但一遇到需要逻辑推理的生成任务就频频翻车。
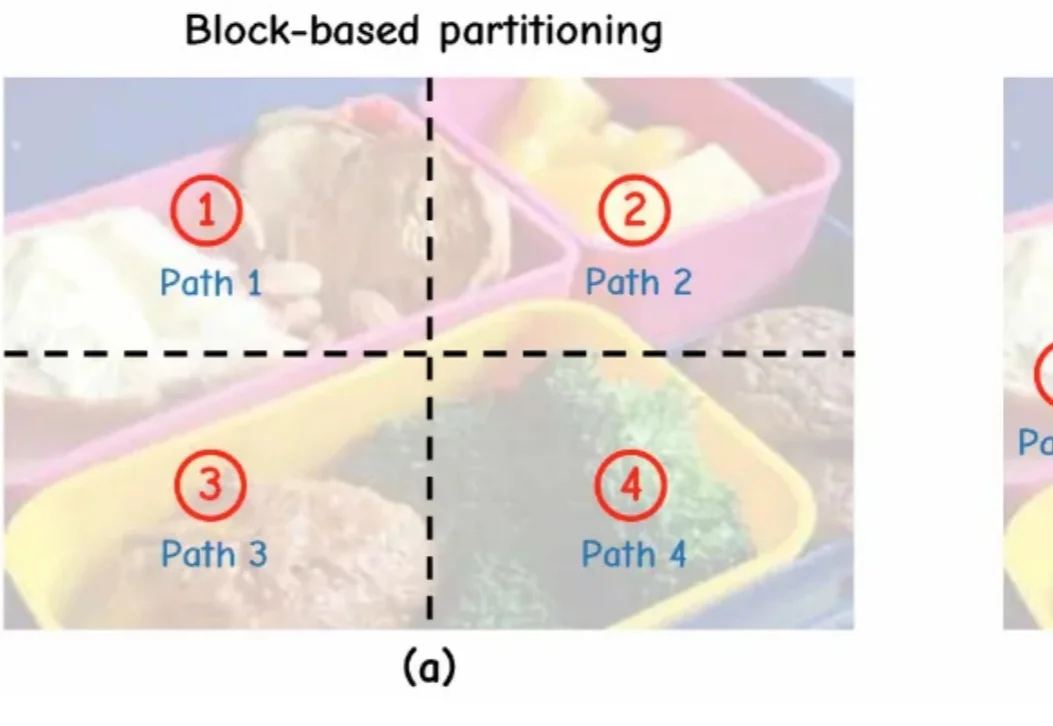
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。

一睁眼!陈天桥带队的大模型黑马MiroMind再度满血归来—— 正式发布新一代重型推理智能体:MiroThinker-1.7和MiroThinker-H1。
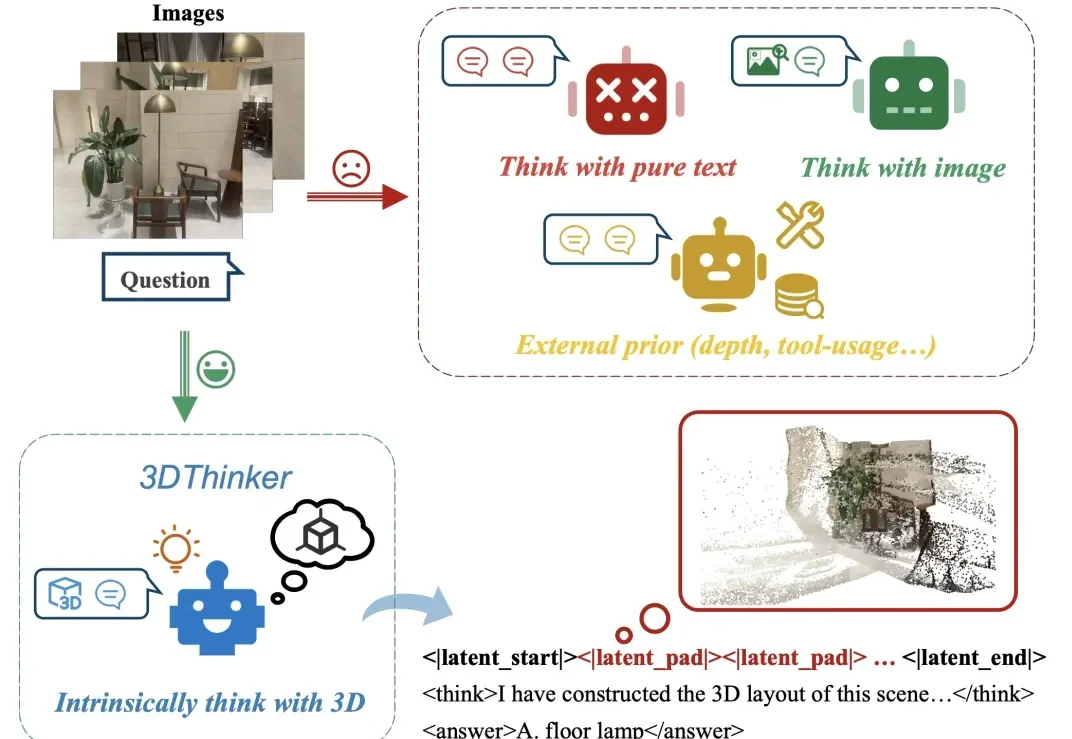
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。
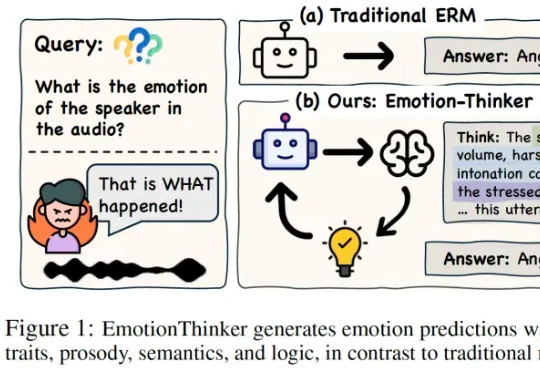
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。

美团也重磅更新自家模型 ——LongCat-Flash-Thinking-2601。这是一款强大高效的大规模推理模型,拥有 5600 亿个参数,基于创新的 MoE 架构构建。该模型引入了强大的重思考模式(Heavy Thinking Mode),能够同时启动 8 路思考并最终总结出一个更全面、更可靠的结论。目前重思考模式已在 LongCat AI 平台正式上线,人人均可体验。
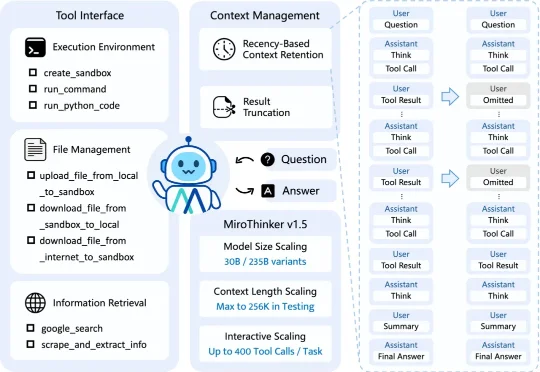
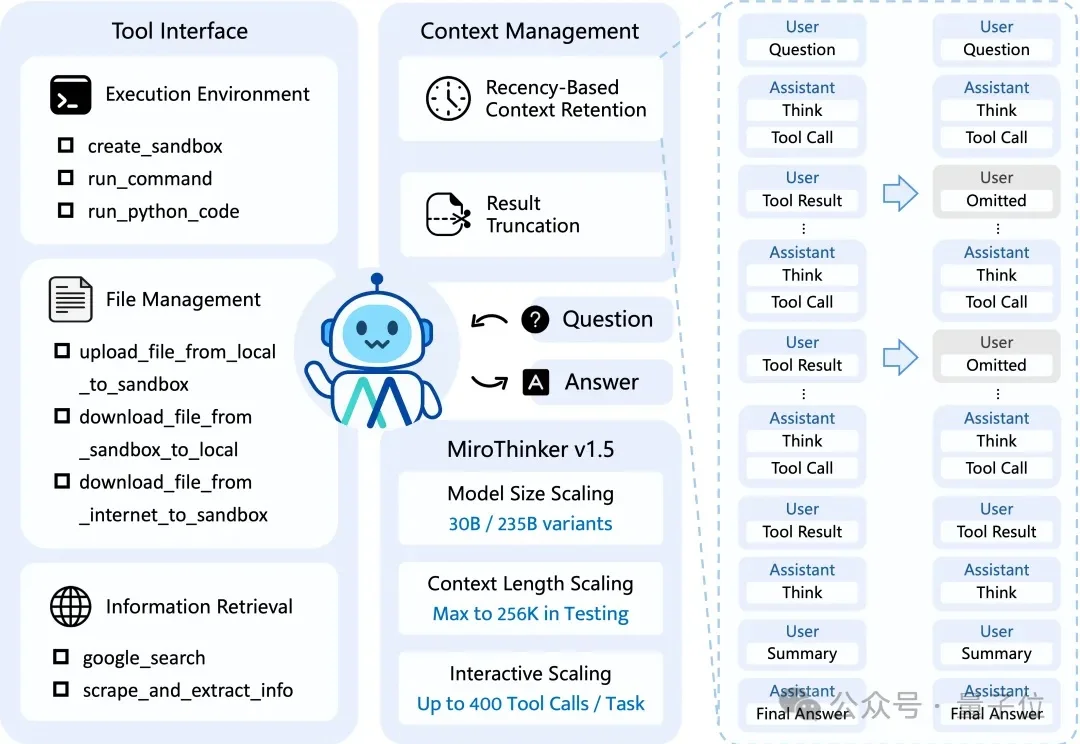
2026年1月5日,由陈天桥和清华AI学者代季峰联合发起的MiroMind团队,正式发布了自研旗舰搜索智能体模型MiroThinker 1.5。这个消息本身并不算特别,毕竟最近几个月几乎每周都有新模型发布。但当我深入了解后发现,这个模型背后代表的思路,可能会彻底改变我们对AI能力边界的认知。
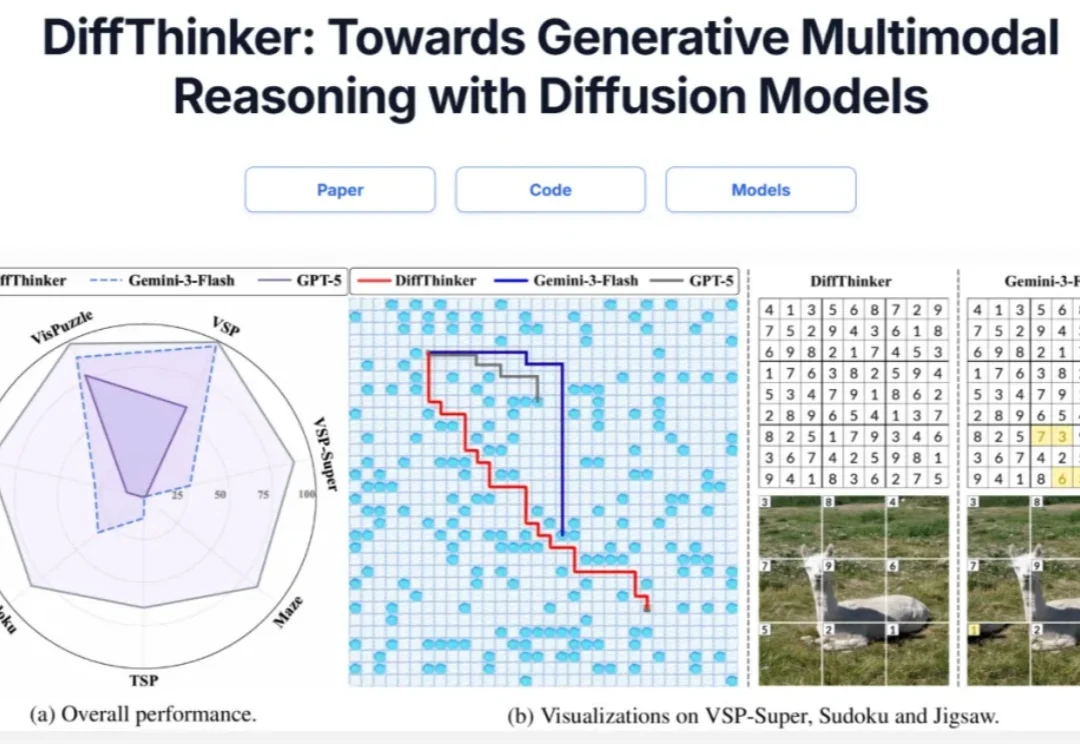
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
新年刚至,陈天桥携手代季峰率先打响开源大模型的第一枪。