
立足「宠物第一视角」,上海交大团队「Auren」用AI硬件打通人宠情感联结
立足「宠物第一视角」,上海交大团队「Auren」用AI硬件打通人宠情感联结海内外资本正在同步加码AI宠物硬件。AI情绪翻译项圈Traini斩获英伟达、谷歌、Meta等高管的投资,国内的MOVA、Pettichat、PurrPurr、SATELLAI、Loona今年也接连吸金。
来自主题: AI资讯
7278 点击 2026-06-24 10:54
 搜索
搜索
海内外资本正在同步加码AI宠物硬件。AI情绪翻译项圈Traini斩获英伟达、谷歌、Meta等高管的投资,国内的MOVA、Pettichat、PurrPurr、SATELLAI、Loona今年也接连吸金。

亚马逊于 2020 年推出的 AI 加速芯片 Trainium 已赢得包括 OpenAI、Anthropic 及优步科技在内的数家重量级客户,这些企业均通过亚马逊云服务使用该硬件。亚马逊表示,该芯片已带来超过 2250 亿美元的收入承诺。
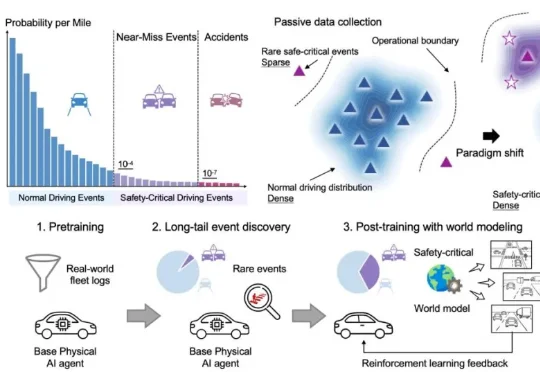
香港大学李弘扬团队联合华为、上海创智学院及清华大学李升波教授团队,发表的最新论文World Engine: Towards the Era of Post-Training for Autonomous Driving给出了系统回答。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——
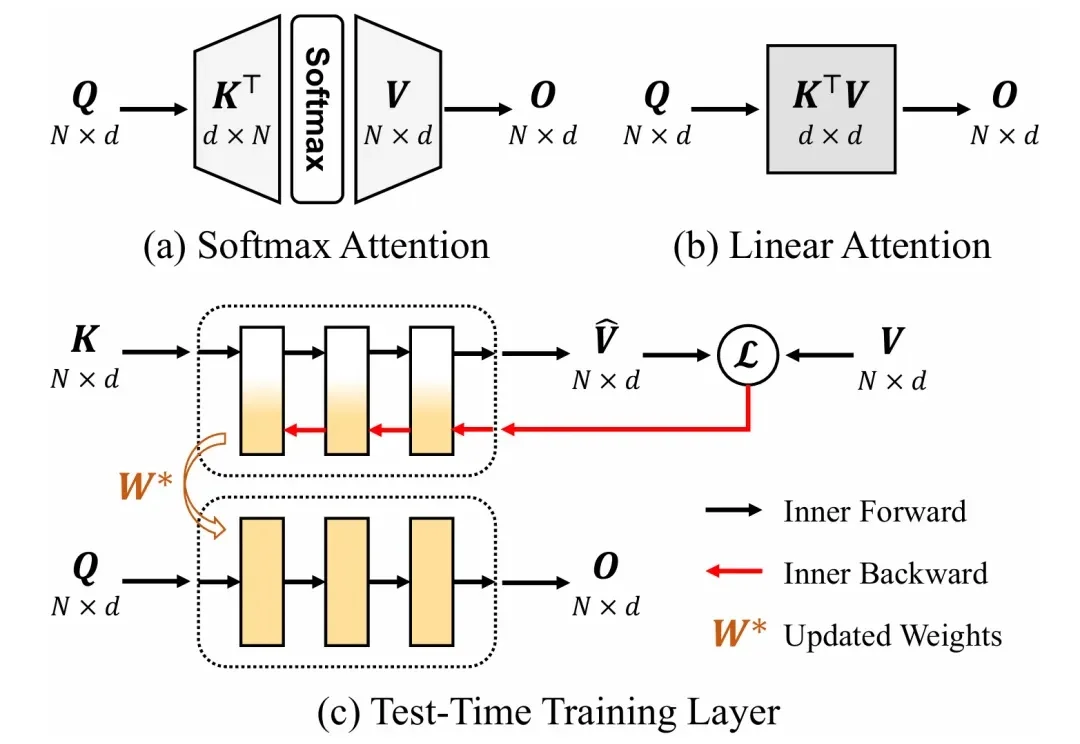
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!