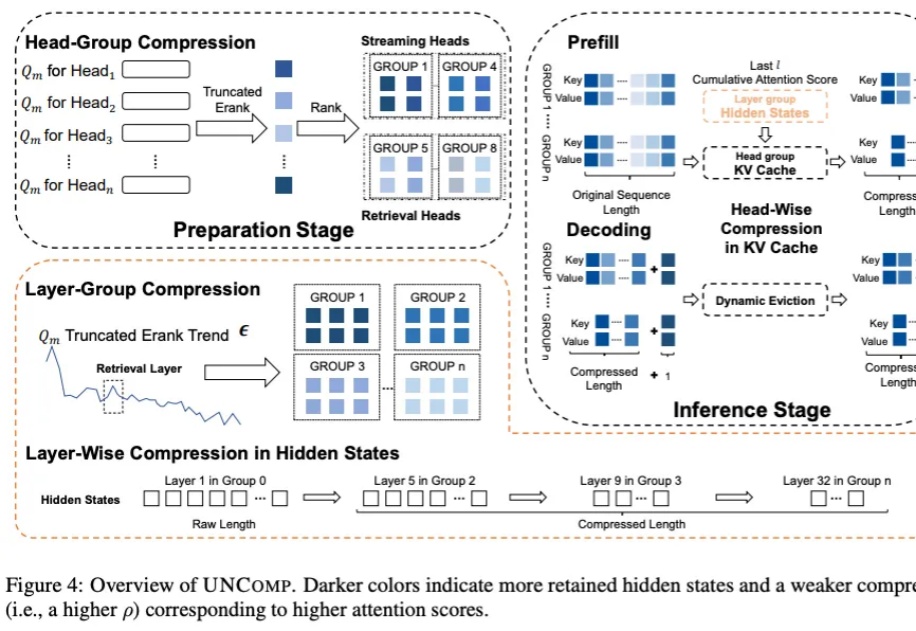
跨层压缩隐藏状态同时加速TTFT和压缩KV cache!
跨层压缩隐藏状态同时加速TTFT和压缩KV cache!我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
来自主题: AI技术研报
10024 点击 2025-11-13 15:19
 搜索
搜索
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?