
RAE的终极形态?北大&阿里提出UniLIP: 将CLIP拓展到重建、生成和编辑
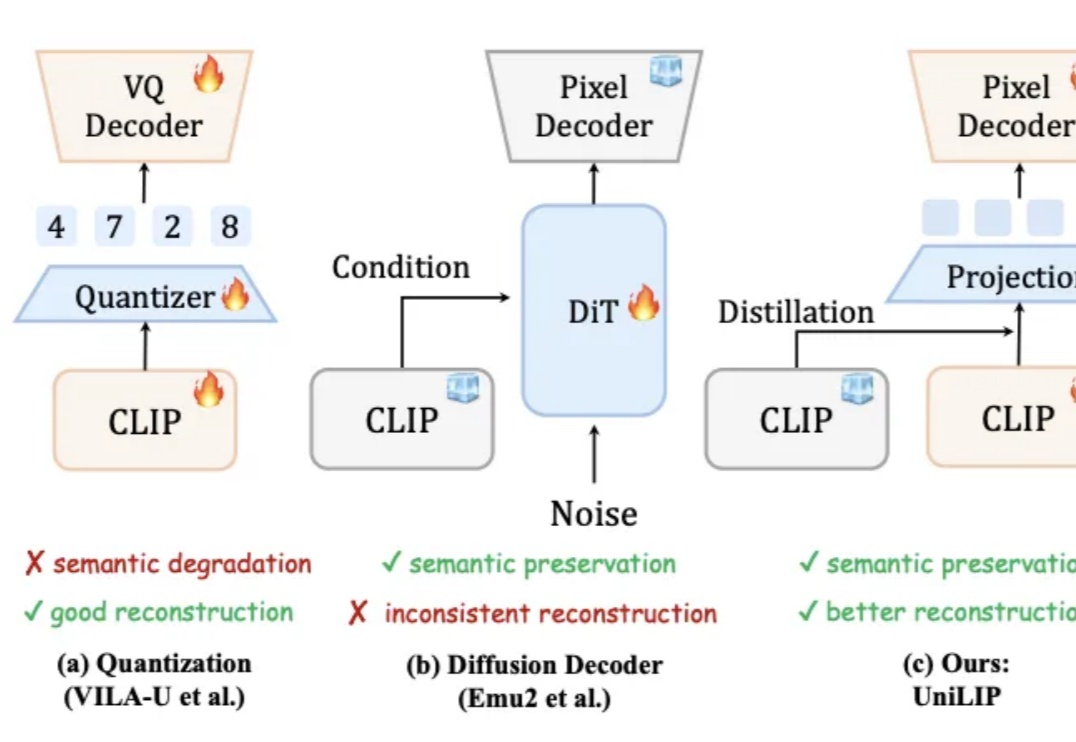
RAE的终极形态?北大&阿里提出UniLIP: 将CLIP拓展到重建、生成和编辑统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。
来自主题: AI技术研报
9203 点击 2025-11-03 09:50