# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。
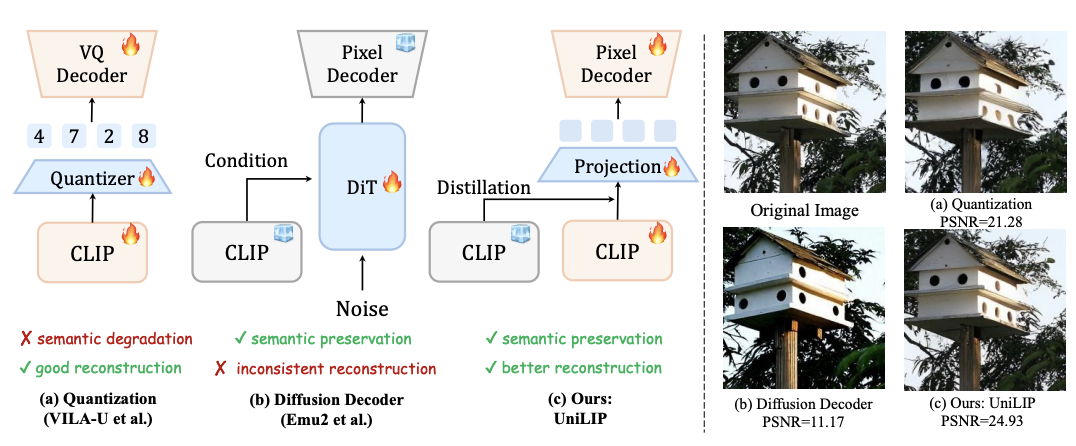
为解决这一核心矛盾,UniLIP 提出创新的 CLIP 微调框架,通过两阶段重建训练与自蒸馏损失,在不损失模型原有理解性能的同时,实现了卓越的图像重建能力。UniLIP 可直接替换 MLLM(如 InternVL)中的原有 CLIP 模块(如 InternViT),并保持甚至略微提升其理解性能。
不同于 RAE 仅在 ImageNet 上进行了实验,UniLIP 进行了大规模的生成和编辑训练。UniLIP 仅用 1B 和 3B 参数的模型,便在 GenEval (0.90)、WISE (0.63) 和 ImgEdit (3.94) 等多个基准上取得了 SOTA 性能,媲美甚至超越了更大规模的模型。

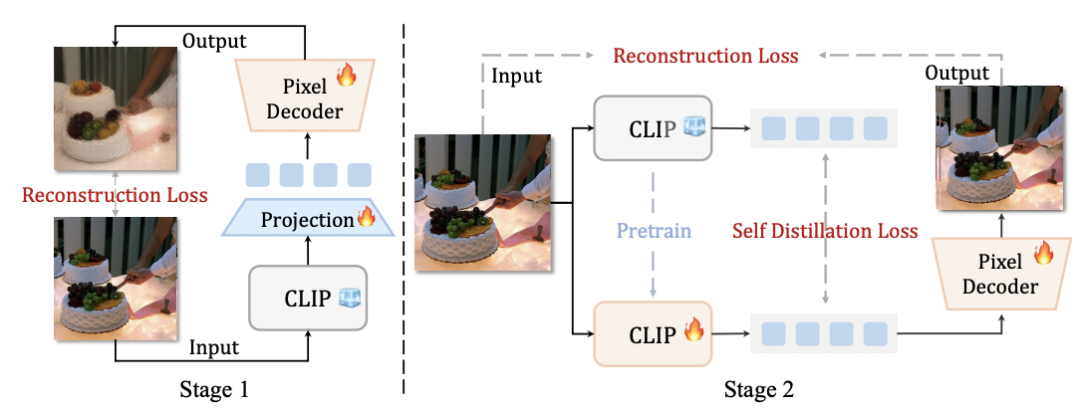
为解决 CLIP 特征因细节缺失导致的重建模糊问题,UniLIP 提出了一种创新的两阶段训练方案,旨在增强其像素级重建能力,同时不损害其卓越的语义理解力。该方案基于一个包含 CLIP、像素解码器及投影层的自编码器架构。
第一阶段:解码器对齐。 此阶段冻结 CLIP,仅训练像素解码器和投影层,使其学习从固定的 CLIP 特征中重建图像。训练目标为:
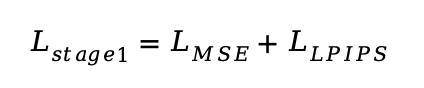
第二阶段:自蒸馏微调。 由于原始 CLIP 特征缺乏像素细节,第一阶段的重建质量受限。因此,此阶段将共同训练 CLIP,并通过自蒸馏方法约束其特征,防止其偏离原始分布,从而在注入细节的同时保留语义。训练目标为:
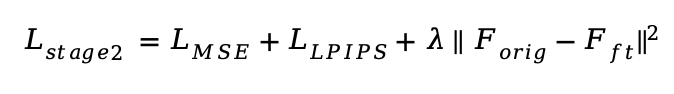
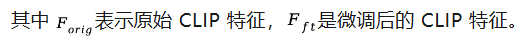
通过此方案,UniLIP 克服了语义理解与像素重建的内在权衡,其理解能力甚至在部分基准上得到增强(见下表)。对于生成与编辑任务,UnLIP 特征带来了三大优势:
(1)高保真压缩:实现 32 倍图像压缩,并能通过轻量级解码器高质量恢复。
(2)强文本对齐:继承 CLIP 的对齐能力,确保对文本指令的精准响应。
(3)完备特征表示:同时编码高级语义与像素细节,为高保真编辑提供完整信息。

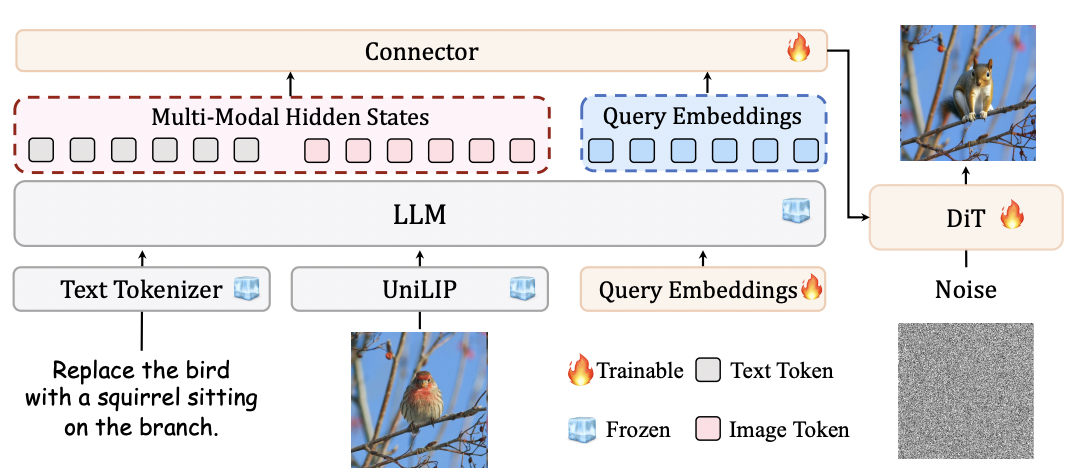
UniLIP 借鉴了 MetaQuery 范式,但突破了其在图像编辑任务中的信息瓶颈。传统方法仅用固定数量的查询嵌入(Query Embeddings)连接 MLLM 与扩散模型,这在传递参考图像丰富的像素级细节时力不从心,常导致编辑结果细节退化或内容不一致。
为此,UniLIP 提出了一种双条件架构。该架构在查询嵌入之外,额外引入 MLLM 的多模态隐藏状态作为第二个条件,共同引导 DiT 的交叉注意力模块。这有效地补充了缺失的像素级信息。这种设计成功地将复杂任务解耦:MLLM 专注于高级推理和意图理解,DiT 则基于这套无损传递的、兼具高级语义与底层细节的丰富线索,进行高保真度的图像合成。最终,UniLIP 在图像生成与编辑任务上均实现了卓越性能。
模型架构
UniLIP 包括 1B 和 3B 两个模型变体,它们分别由 InternVL3 (1B/2B) 与 SANA (0.6B/1.6B) 集成而来。在架构上,UniLIP 直接采用 InternVL3 的 InternViT 作为 CLIP 编码器,并结合 DC-AE 的像素解码器。连接器则设计为 6 层,结构与 LLM 保持一致,并使用了 256 个可学习查询。
训练数据
UniLIP 的生成数据来自 BLIP3-o,包括 38M 的预训练数据和 60k 的指令微调数据。UniLIP 的编辑预训练数据来自 GPT-Image-Edit-1.5M,指令微调数据来自包含 46K 编辑数据的 ShareGPT-4o-Image。
图像重建
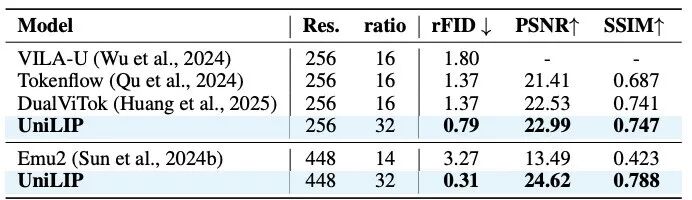
在 256x256 分辨率下,UniLIP 不仅超越了此前的量化方法,其更高的下采样率也带来了生成效率优势。在 448x448 分辨率下,与使用扩散解码器的 Emu2 相比,UniLIP 由于打开 CLIP 进行重建训练取得显著优势。
多模态理解
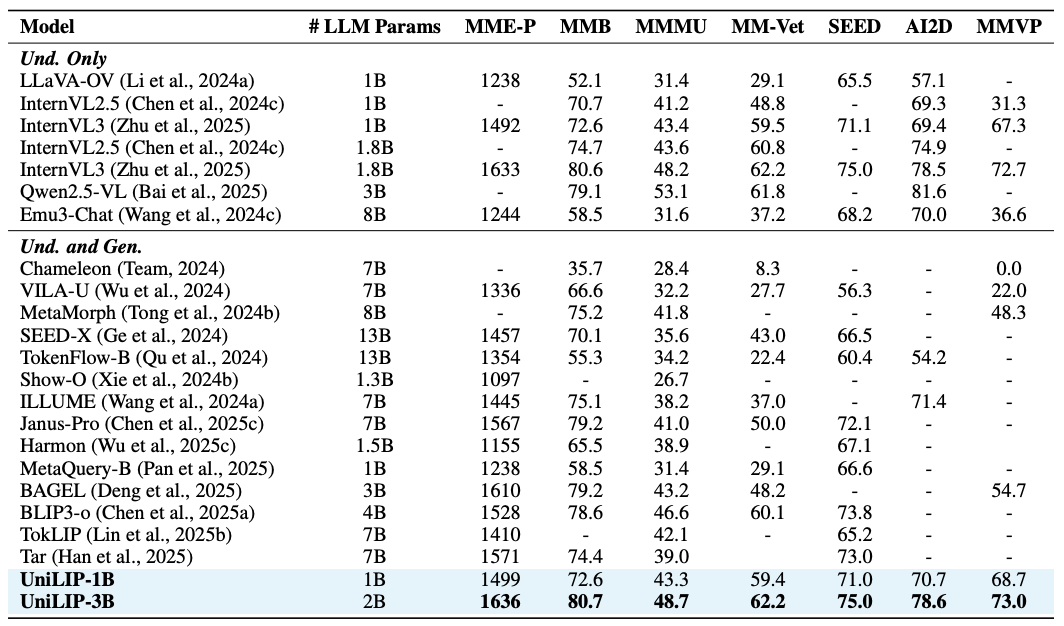
UniLIP 可以直接替换 InternVL 的视觉编码器在理解基准上进行测试。得益于重建训练对原始能力的有效保持,UniLIP 实现了同规模最好的理解性能,并且超越了 Tar (7B) 和 VILA-U (7B) 等采用量化 CLIP 特征的更大模型。
图像生成
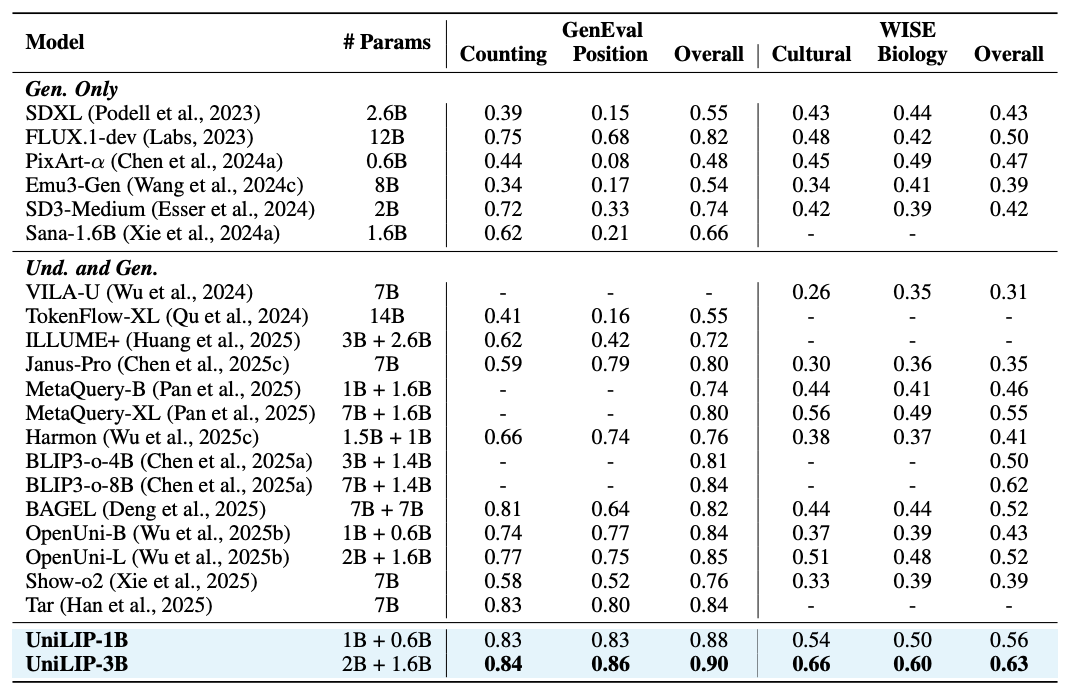
在 GenEval (0.90) 和 WISE (0.63) 图像生成基准上,UniLIP 凭借卓越的文图对齐能力,不仅超越了同规模模型,还达到了与 BAGEL 等更大模型相当的水平。
图像编辑
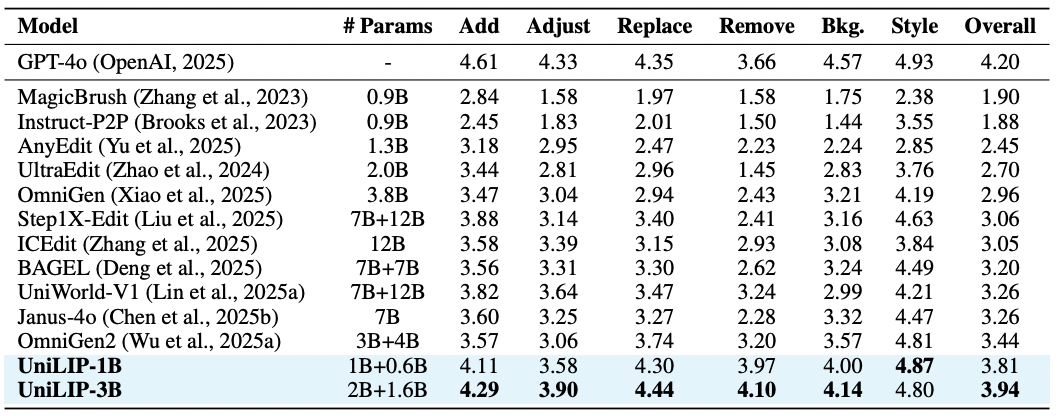
在 ImgEdit-Bench 图像编辑基准上,UniLIP 以 3.94 的高分超越了 OmniGen2 等先进模型。其强大性能归功于 UniLIP 特征的丰富细节与精准语义对齐能力。UniLIP 创新的双条件架构充分利用了这些特征,确保了编辑的精确性和非编辑区的一致性。

在生成任务中,UniLIP 可以生成美观且严格遵循用户提示的图像;而在编辑任务中,UniLIP 可以在准确修改图像的同时保持周围区域的一致性。
通过精心设计的两阶段训练与自蒸馏约束,UniLIP 有效解决了语义理解与像素细节保留的矛盾。此外,其创新的双条件架构无缝连接了 MLLM 与扩散模型,确保了生成和编辑任务中的高保真度与一致性。UniLIP 在多个基准上展示的卓越性能,为下一代统一多模态模型提供了新的范式。
文章来自于“机器之心”,作者 “汤昊”。


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
