VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
来自主题: AI技术研报
7380 点击 2025-10-29 16:28
 搜索
搜索
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。

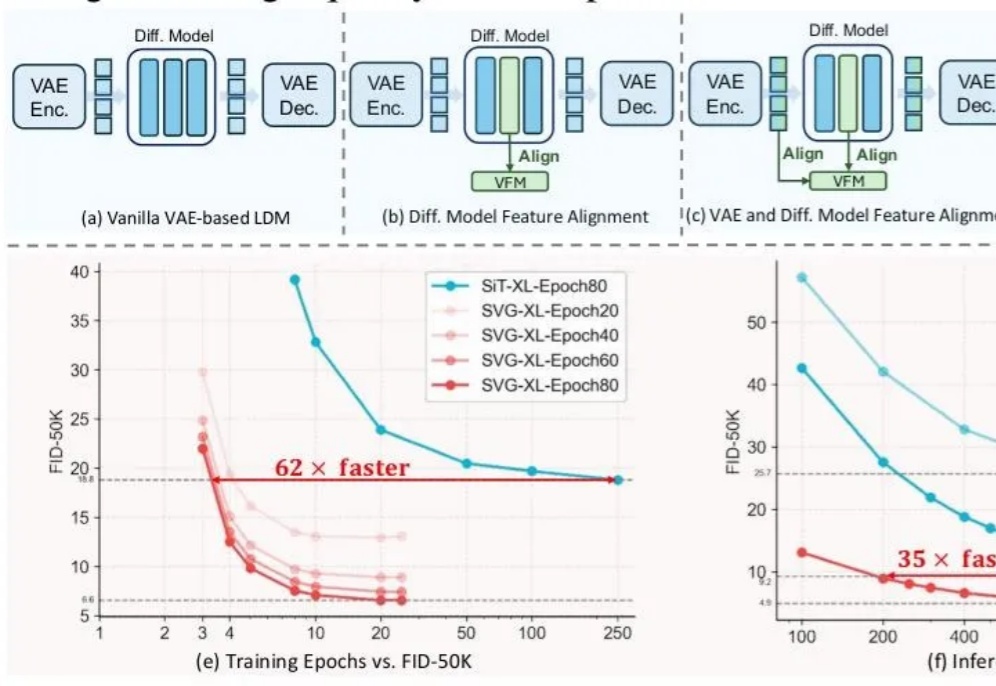
长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练
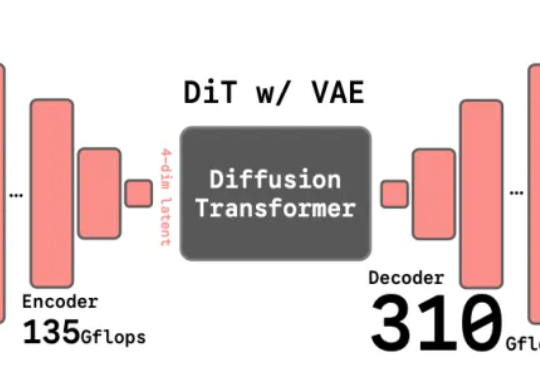
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。
今天凌晨,阿里推出了最新图像编辑模型 Qwen-Image-Edit!该模型基于 200 亿参数的 Qwen-Image 架构构建,支持中英文双语精准文本编辑,在保持原有风格的同时完成修改。此外,Qwen-Image-Edit 将输⼊图像同时输⼊到 Qwen2.5-VL(实现视觉语义控制)和 VAE Encoder(实现视觉外观控制),兼具语义与外观的双重编辑能⼒。

统一图像理解和生成,还实现了新SOTA。
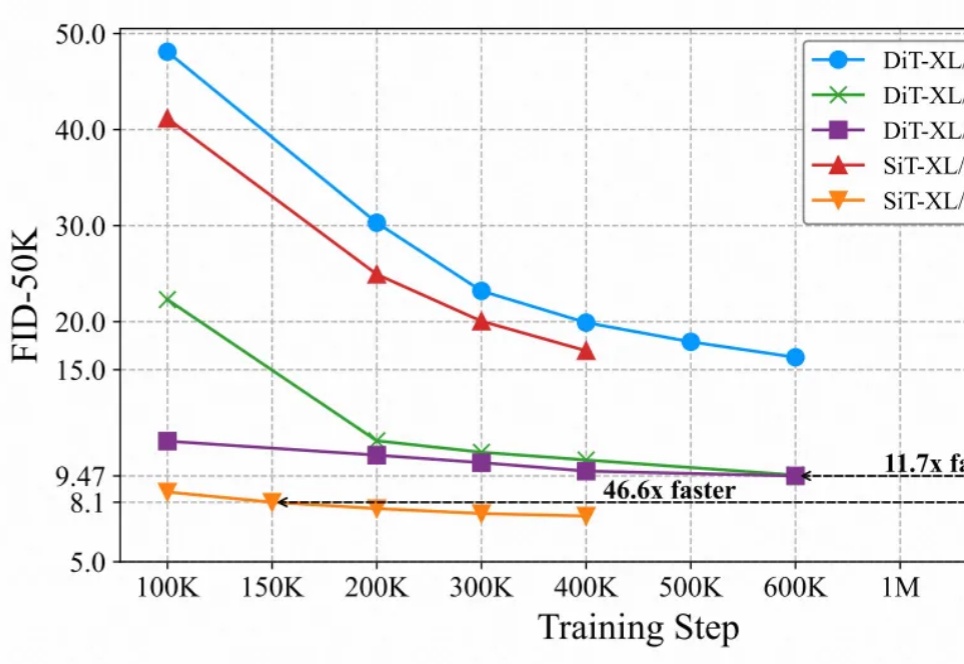
最近的研究强调了扩散模型与表征学习之间的相互作用。扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。

港科大团队重磅开源 VideoVAE+,提出了一种强大的跨模态的视频变分自编码器(Video VAE),通过提出新的时空分离的压缩机制和创新性引入文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持很好的时间一致性和运动恢复。
Open-Sora-Plan迎来又一次升级。新的Open-Sora-Plan v1.3.0版本引入了五个新特性:性能更强、成本更低的WFVAE;Prompt refiner;高质量数据清洗策略;全新稀疏注意力的DiT,以及动态分辨率、动态时长的支持。

在生成式模型的迅速发展中,Image Tokenization 扮演着一个很重要的角色,例如Diffusion依赖的VAE或者是Transformer依赖的VQGAN。这些Tokenizers会将图像编码至一个更为紧凑的隐空间(latent space),使得生成高分辨率图像更有效率。

当地时间5月7日,ICLR 2024颁发了自大会举办以来的首个「时间检验奖」!