联手OpenAI,吴恩达推出一门o1推理新课程,还免费
联手OpenAI,吴恩达推出一门o1推理新课程,还免费在刚刚过去的 2024 年,OpenAI 推出了 o 系列模型。相比于以往大型语言模型,o 系列模型使用更多的计算进行更深入的「思考」,能够回答更复杂、更细致的问题。
来自主题: AI资讯
9922 点击 2025-01-02 14:53
 搜索
搜索
在刚刚过去的 2024 年,OpenAI 推出了 o 系列模型。相比于以往大型语言模型,o 系列模型使用更多的计算进行更深入的「思考」,能够回答更复杂、更细致的问题。
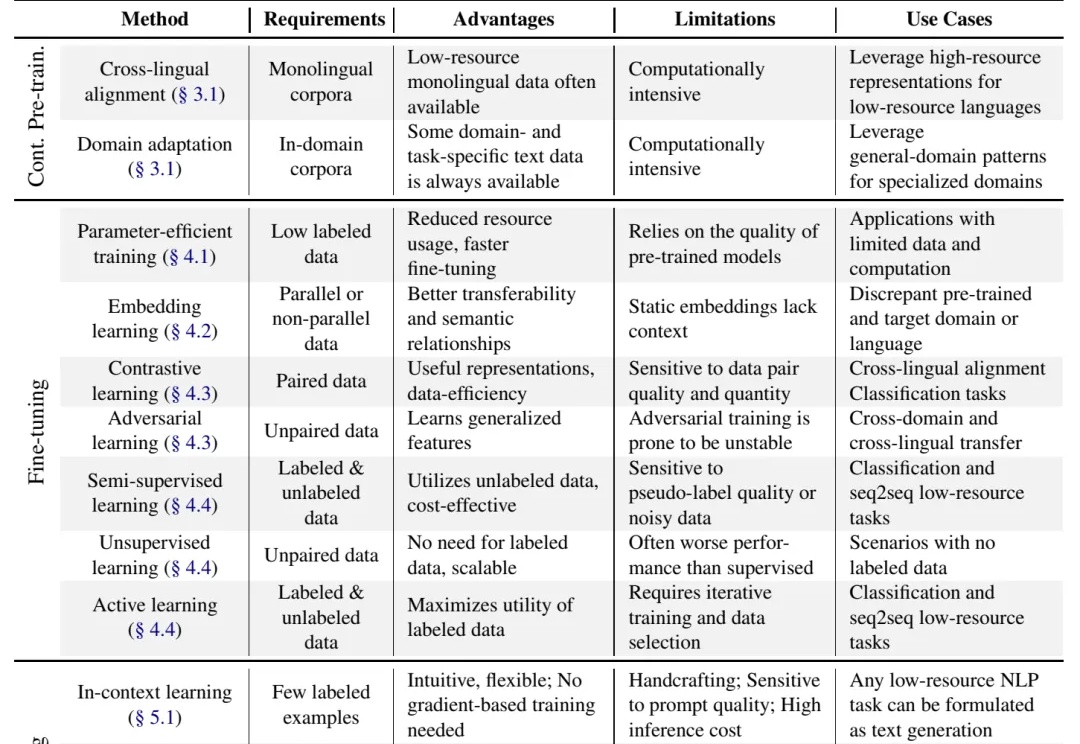
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。

数学大佬陶哲轩和OpenAI两位高管最近进行了一场线上对谈,主题为“The Future of Math with o1 Reasoning”,即以推理为主的o1模型如何与数学融合,从而解锁突破性的科学进步。
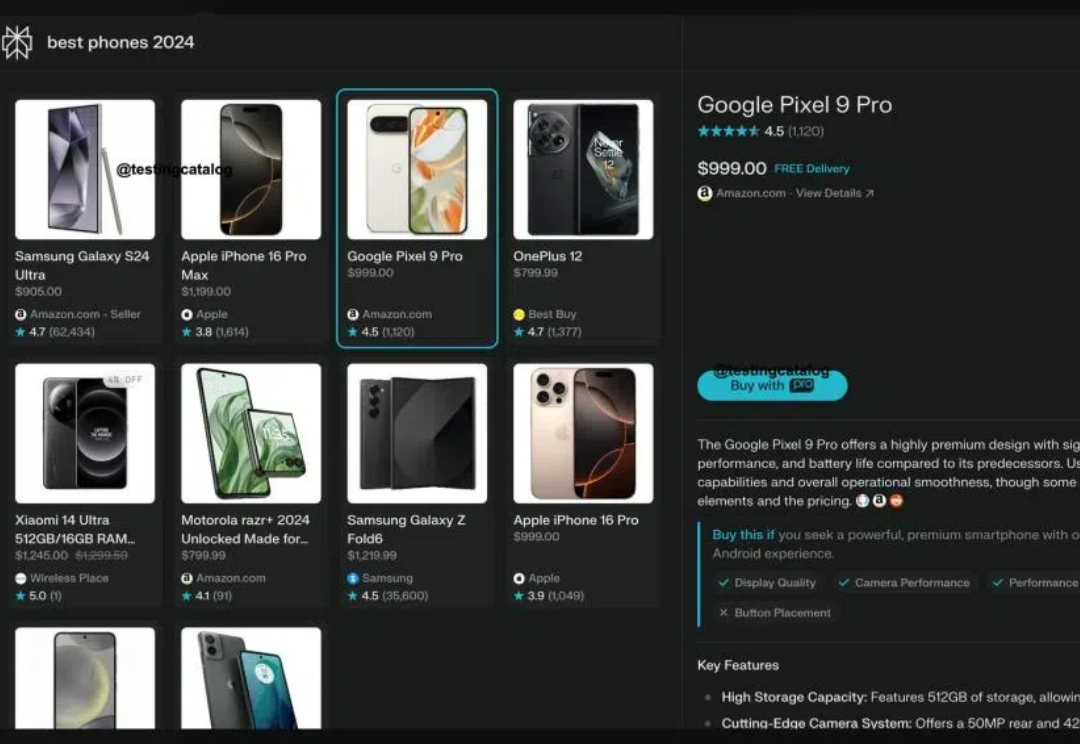
周一,Perplexity又放出了一个大招,宣布推出会员购物功能“Buy with Pro”。
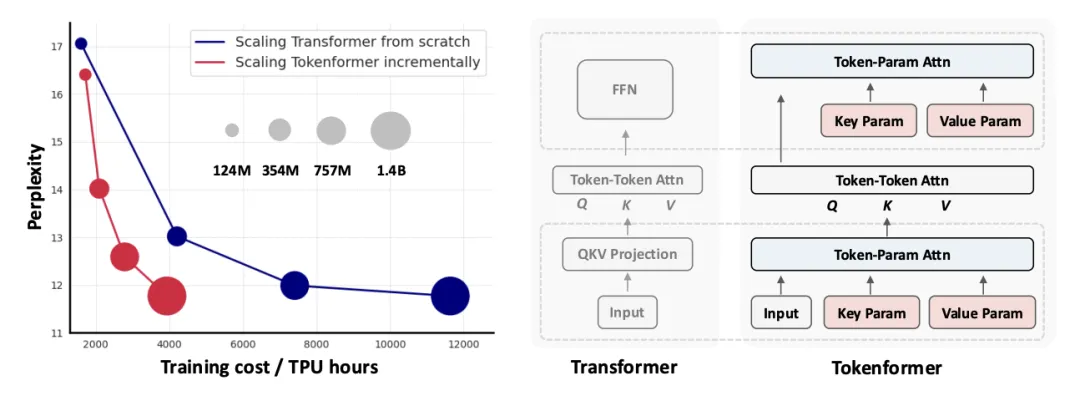
新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。
Notion 今天举行了一个叫 Make with Notion 的发布会,这次发布会发布了一系列的新功能和产品,包括了表单(Forms)、布局(Layouts)、自动化(Automations)、Notion AI、交易市场(Marketplace) 以及大家最期待的 Notion Email。

这是一轮新变化。

2020 年,谷歌发表了预印本论文《Chip Placement with Deep Reinforcement Learning》,介绍了其设计芯片布局的新型强化学习方法。后来在 2021 年,谷歌又发表在 Nature 上并开源了出来。
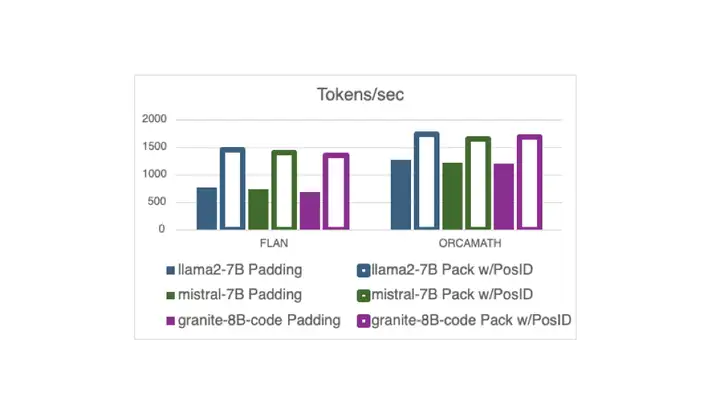
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!