
在WAIC,十大开源社区「挤」进了一个GPU展台
在WAIC,十大开源社区「挤」进了一个GPU展台沐曦也把今年的新东西几乎一次性搬到了现场。曦景S600超节点首次亮相,单机柜64张GPU、可扩展至万卡集群;AI4S方向的曦索X300系列科学智能GPU首次发布;Agent体验区排起长队,数字员工、AI文创工作站几乎没停过。
来自主题: AI资讯
8788 点击 2026-07-19 10:10
 搜索
搜索
沐曦也把今年的新东西几乎一次性搬到了现场。曦景S600超节点首次亮相,单机柜64张GPU、可扩展至万卡集群;AI4S方向的曦索X300系列科学智能GPU首次发布;Agent体验区排起长队,数字员工、AI文创工作站几乎没停过。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。
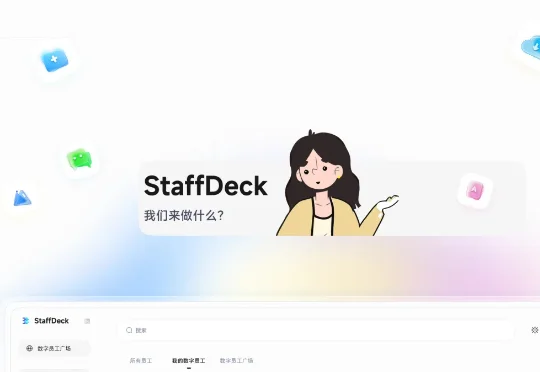
为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。

WAIC 前夕,星尘智能(Astribot)新模型 Lumo-2,直接在官网甩出 20 + 真机视频 ——这背后,是星尘智能发布的第二代具身基座模型,也是业内首个面向家庭场景的隐式世界 - 动作模型(Latent World-Action Model),同步发的,还智能体 Agent Philia。
这一次,我就挑选了其中比较有代表性的三款:QClaw、WorkBuddy 和百度搭子,通过几组真实办公任务进行横向测试,看看国产办公 Agent 现在到底发展到了什么水平。横测标准:同一任务、同一素材、同一交付标准,每个任务只给一次主要执行机会。

Nile(https://nile.shop),这家15人的创业公司,想要帮助解决这个问题。他们要为品牌构建一个“AI原生后端”,让商家拥有属于自己的、能面向任何Agent做分发的“品牌智能体”。

最近,我和一位来北京融资,做出海营销 Agent 的创业者聊天。

昨天那篇文章,我说了一下我现在用Agent的日常。
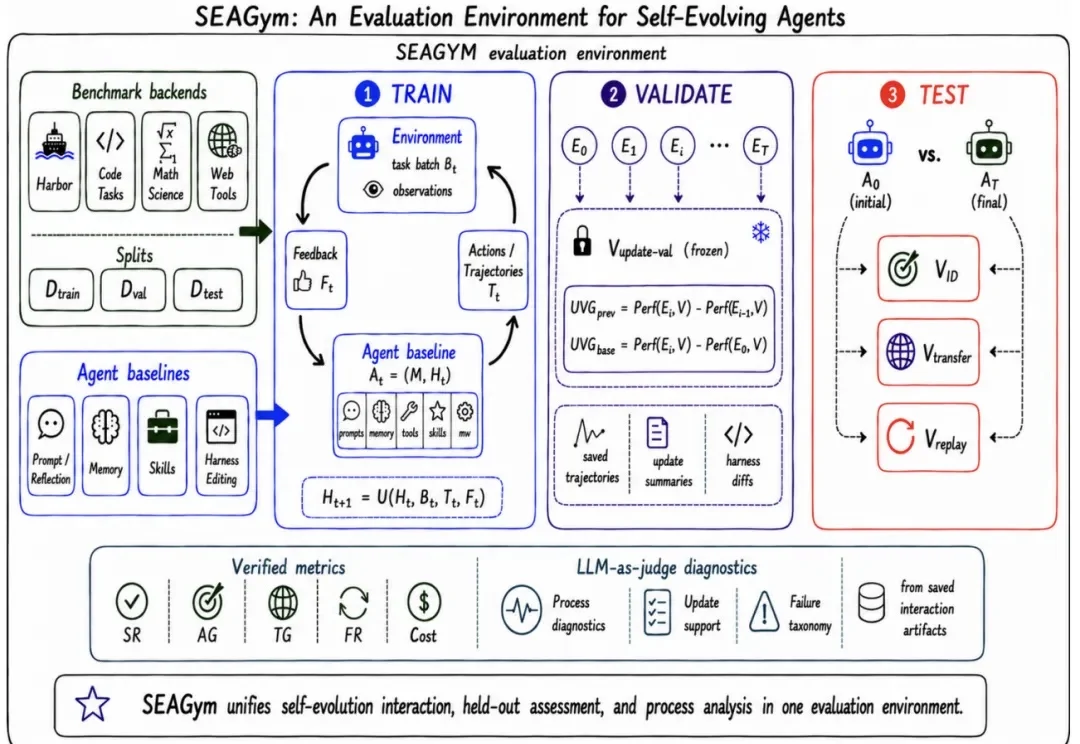
近日,翁荔发布长文 《Harness Engineering for Self-Improvement》,系统梳理了 harness engineering 在 AI 自我改进中的作用。

Raft是一个很神奇的AI产品。当它还叫Slock的时候,我认为这主要是一个投资人自嗨产物。除了极少数自己充了Claude、Codex会员,同时本地电脑还有Opencode、Pi等一系列Agent的极致变态电子佬用户,没人需要一个AI群聊。