
AI找出4种全新超导体,只用28个GPU时!人类此前完全未知
AI找出4种全新超导体,只用28个GPU时!人类此前完全未知刚刚,阿里达摩院联合中国人民大学高瓴人工智能学院、中国科学院大学等机构,发布了首个专攻超导材料发现的AI智能体“ElementsClaw”(元素虾)。只用了28个GPU小时,ElementsClaw就给已知的240万种稳定晶体统统海选了一遍,预测其中的6.8万种可能是超导体。
来自主题: AI资讯
7973 点击 2026-07-03 16:10
 搜索
搜索
刚刚,阿里达摩院联合中国人民大学高瓴人工智能学院、中国科学院大学等机构,发布了首个专攻超导材料发现的AI智能体“ElementsClaw”(元素虾)。只用了28个GPU小时,ElementsClaw就给已知的240万种稳定晶体统统海选了一遍,预测其中的6.8万种可能是超导体。

独家获悉,今日,阿里巴巴内部宣布反向禁用Claude。阿里全员被要求卸载Anthropic相关产品,包括Sonnet、Opus、Fable等多个系列模型,以及Claude Code在内的Agent产品。禁令于7月10日正式生效。
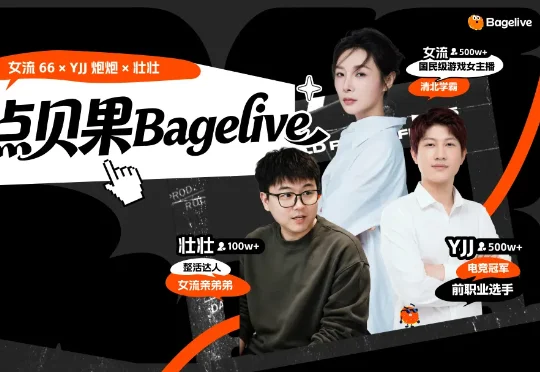
周二晚上,我看了一场完全不一样的直播。知名游戏主播女流66、壮壮,以及电竞冠军 YJJ,一起玩了一场游戏。但这一次,他们不是坐在电脑前操作键盘鼠标,而是直接走进了一个由 AI 搭建出来的"现实游戏世界"。
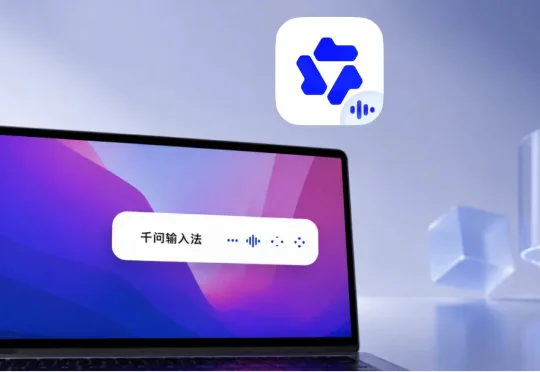
今天发现阿里刚刚把千问输入法做成了独立客户端,上线了 Mac 版本。我第一时间下载体验了一遍。结果比我预期更有意思。安装完成后,不需要登录,免费可用。

今日,QClaw产品负责人张舒昱被曝离职。99年出生的张舒昱完全没有技术背景,是个文科生,但在春节期间策划推出了QClaw,随后爆火。对于她的离职,不少人猜测是“内部赛马”失败。众所周知,在龙虾爆火的时候,腾讯陆续推出了各种龙虾产品,被称为龙虾全家桶。
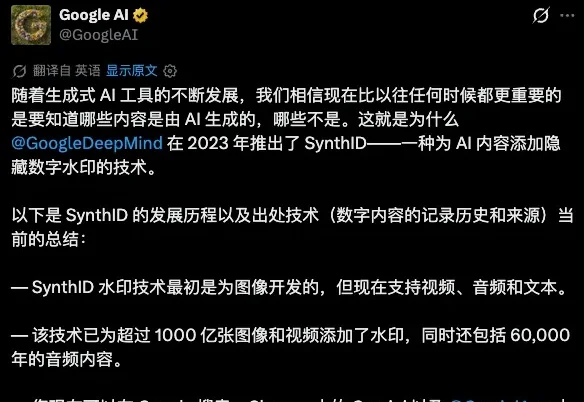
Google AI在X上发了条推文。
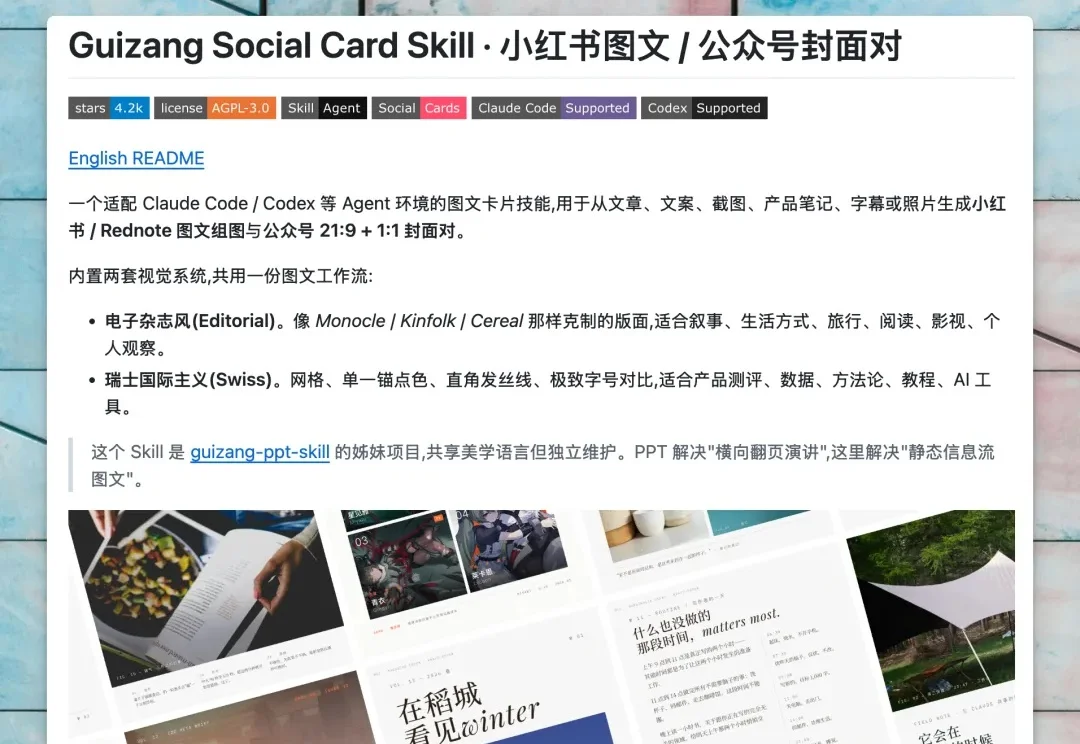
前段时间我做了一个 guizang-social-card-skill(https://github.com/op7418/guizang-social-card-skill)。
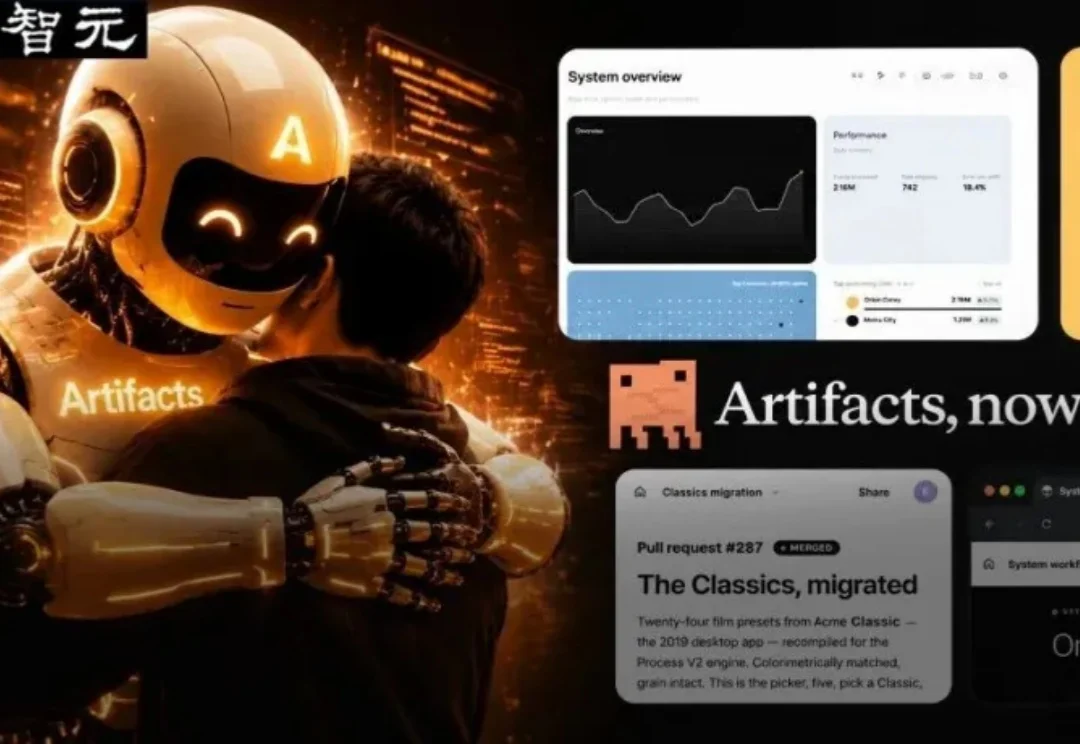
两周前还是大厂团队专属,两周后20刀的Pro用户就能原封不动地用上——Claude Code把「会话实时变网页」这项企业级能力,直接下放到个人用户。

消失19天,Fable 5解禁即翻车!写代码频遭强制降智,魔幻双标气疯开发者。面对离谱的过度审查,这位戴着镣铐的「天才程序员」还值得用吗?

7月2日,据大厂日爆消息,美团内部开始限制使用豆包大模型。消息称,美团向所有涉及到豆包大模型的业务部门下发通知,要求自查并规划迁移至LongCat、DeepSeek等模型,若无法迁移,需单独走审批流程。对此消息,截至发稿,美团暂无官方回应。据媒体报道,这并非美团首次收紧外部大模型的使用。今年4月,美团对内部大模型使用做出调整,不再推荐业务使用阿里云提供的Qwen模型。若业务仍需使用,需上报审批。