
瞄准AI、图形顶端战场:摩尔线程上演国产GPU硬核实力路演
瞄准AI、图形顶端战场:摩尔线程上演国产GPU硬核实力路演这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
来自主题: AI资讯
8931 点击 2025-12-22 17:06
 搜索
搜索
这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
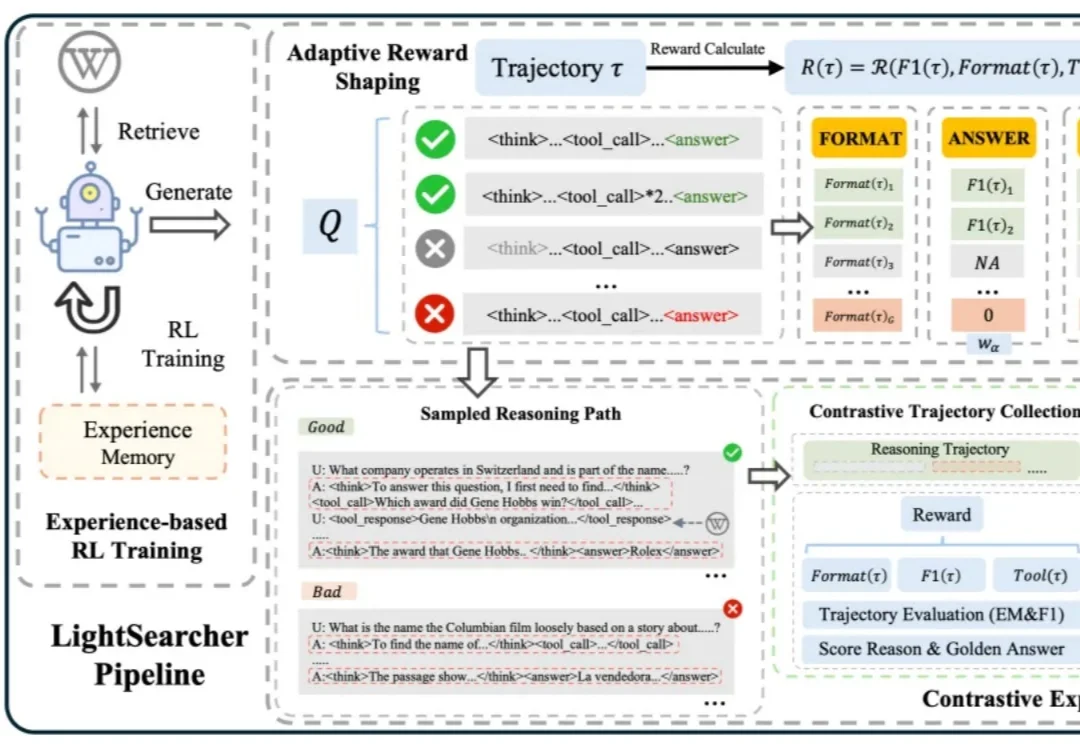
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。
今天,小米发布并开源了最新MoE大模型MiMo-V2-Flash,总参数309B,激活参数15B。今日上午,小米2025小米人车家全生态合作伙伴大会上,Xiaomi MiMO大模型负责人罗福莉将首秀并发布主题演讲。

最近几天,一张开源模型的等级列表在 X 上被疯狂转载。 从夯到拉,国产开源模型排在了数一数二的位置,DeepSeek、Qwen、Kimi、智谱、还有 MiniMax 是全球开源模型的前五名。

从ChatGPT到DeepSeek,AI正沿着“智能+”的路径进入新一轮浪潮。
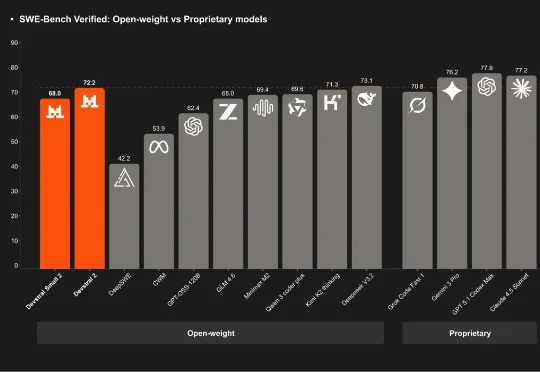
刚刚,「欧洲的 DeepSeek」Mistral AI 再次开源,发布了其下一代代码模型系列:Devstral 2。该系列开源模型包含两个尺寸:Devstral 2 (123B) 和 Devstral Small 2 (24B)。用户目前也可通过官方的 API 免费使用它们。

DeepSeek梁文锋,现在有了新头衔!

刚刚,梁文锋入选《自然》2025年度十大人物榜单!Nature给出的评语是:科技颠覆者!正式报道中,则用「这位中国金融奇才的DeepSeek AI模型惊艳了世界」。
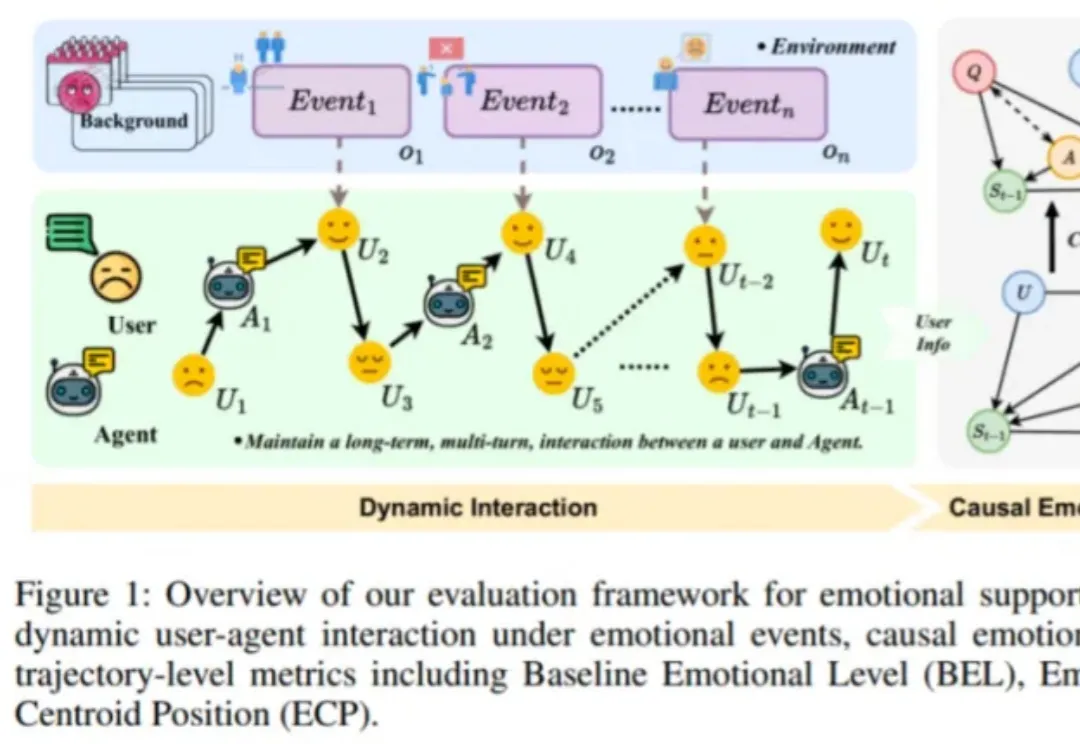
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。