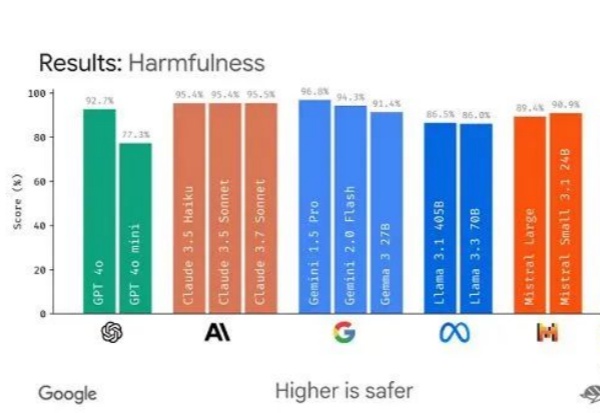
谷歌推出开源框架,要给AI大模型的跑分“立规矩”
谷歌推出开源框架,要给AI大模型的跑分“立规矩”既当裁判员,又当运动员?
来自主题: AI资讯
8874 点击 2025-05-29 09:49
 搜索
搜索
既当裁判员,又当运动员?
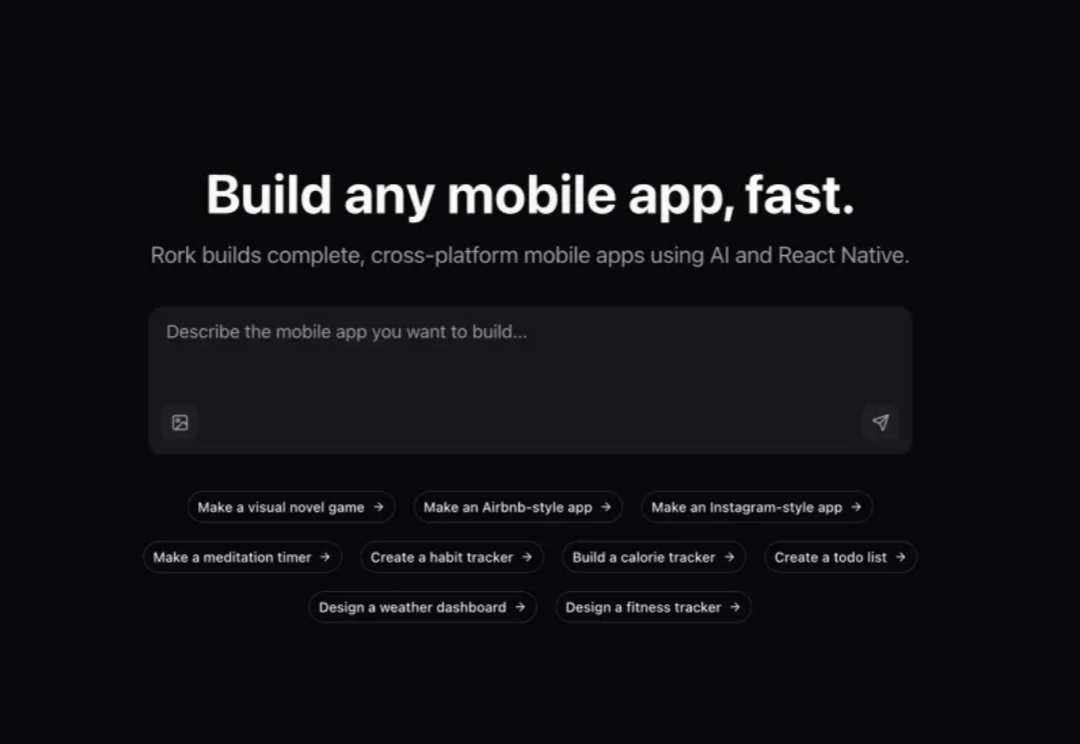
当大多数人还在学习如何使用ChatGPT生成简单文本时,一对年轻创始人已经让AI为你直接构建完整的移动应用。Levan Kvirkvelia和Daniel Dhawan创建的Rork让人想起了硅谷的电影剧情:从信用卡债务缠身、朋友家地板上的床垫,到一条病毒式推文引来百万美元融资,这家初创公司在vibe coding领域掀起了新浪潮。
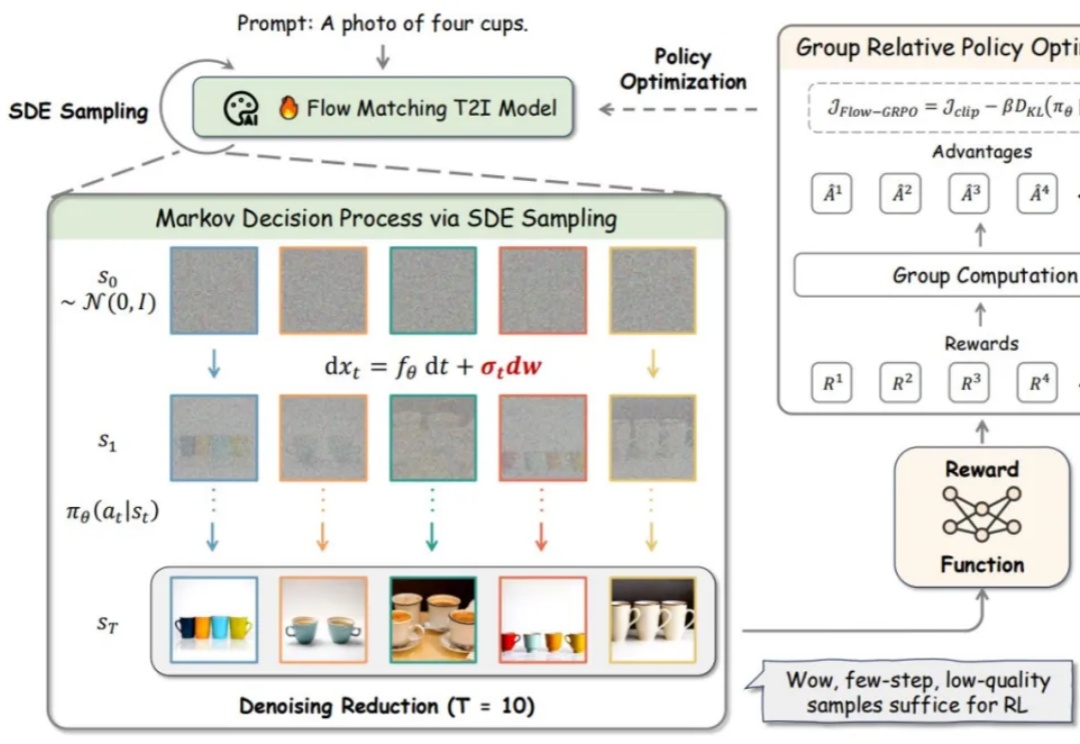
流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。
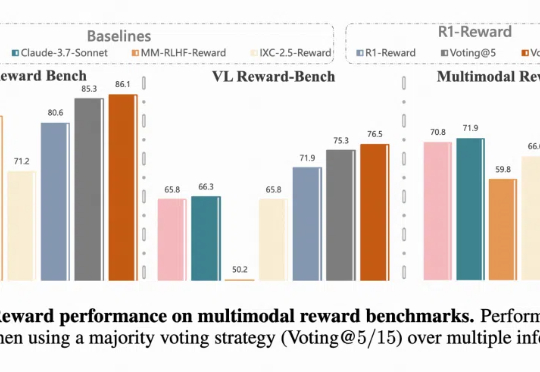
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。

2025 年 4 月的 AI 月报,你会看到:“评估(Evals)” 成为模型和 AI 产品开发的关键词;Google 继续提升 Gemini 模型能力的思路; OpenAI 的 GPT-4o 为什么变得谄媚,以及背后的问题;用户规模与模型能力提升关系不大?可能要有变化了
随着AI Agent 在工作场所日益普及,个人可能会与之紧密协作。波士顿咨询集团报告指出,未来五年内,AI Agent 市场预计将以45%的复合年增长率扩张。
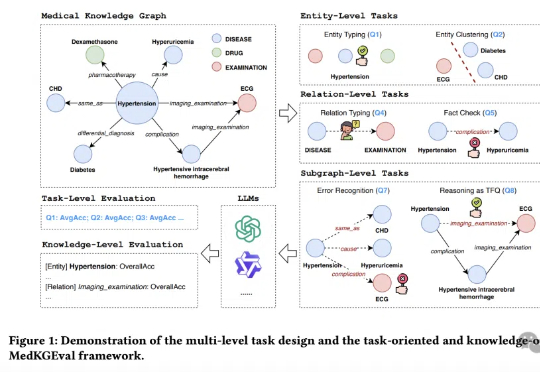
医疗大模型知识覆盖度首次被精准量化!
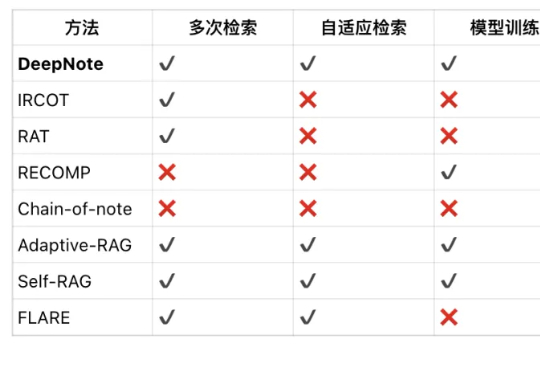
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。

GPT-4o图像生成架构被“破解”了!
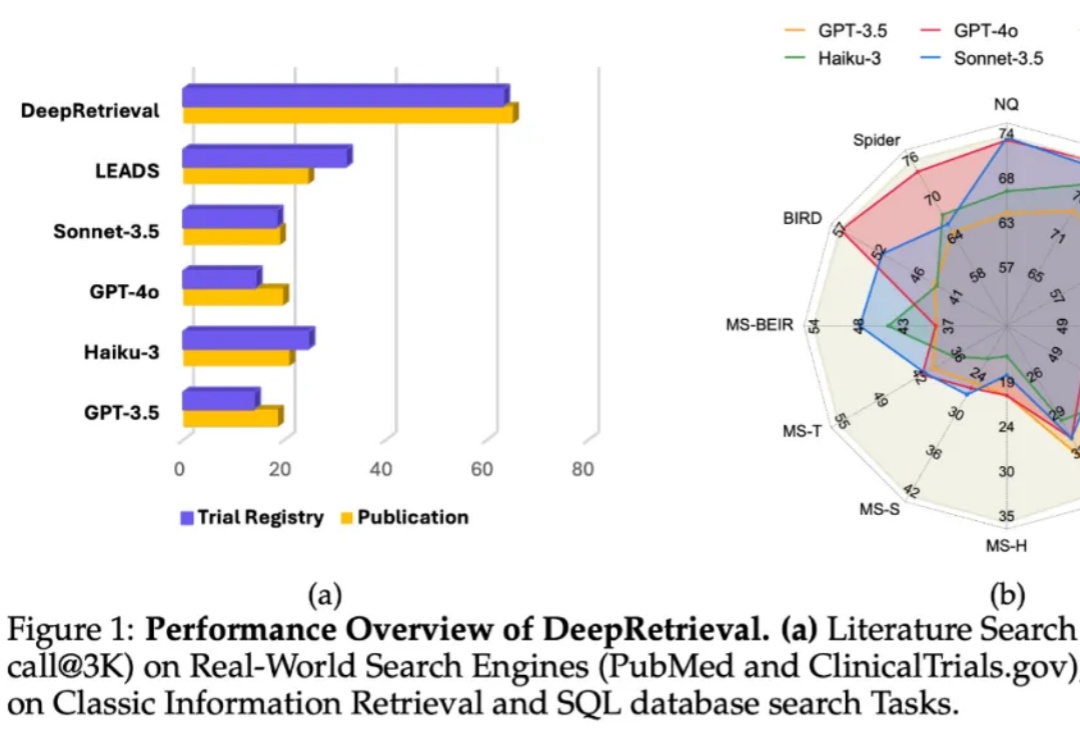
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。