ICML 2026 Oral | 为3D空间智能数据构建全自动数据飞轮,Holi-Spatial打造400万级空间多模态数据集
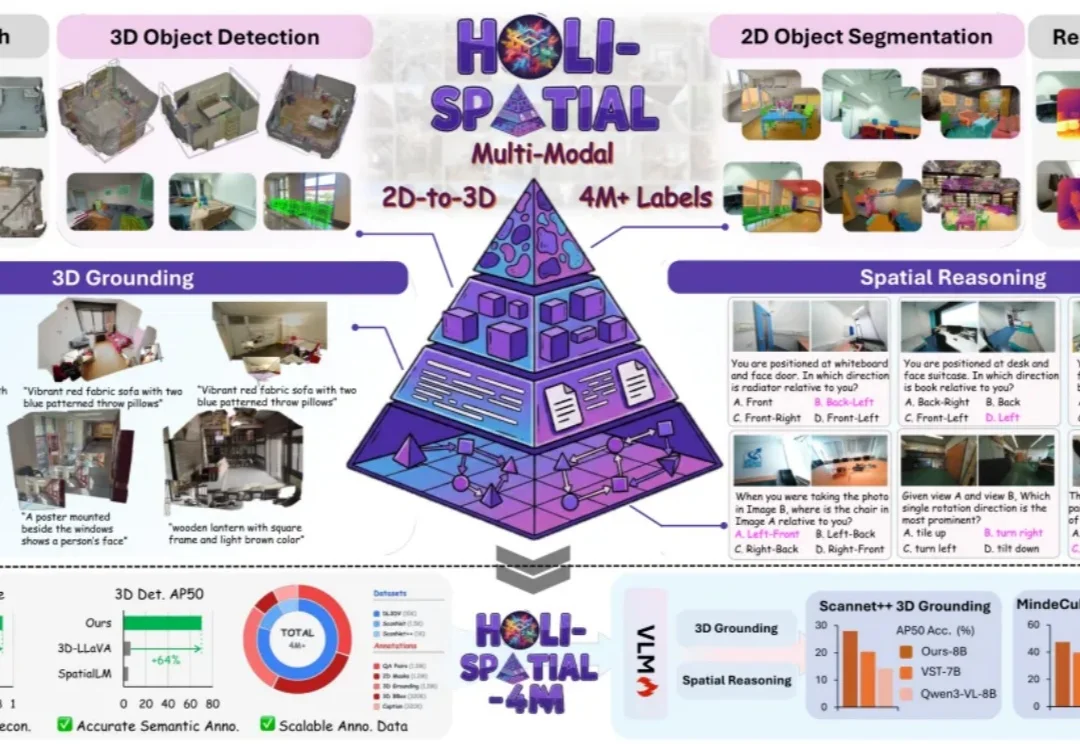
ICML 2026 Oral | 为3D空间智能数据构建全自动数据飞轮,Holi-Spatial打造400万级空间多模态数据集从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。
来自主题: AI技术研报
6985 点击 2026-06-19 10:16