“废弃了7年的老Android项目,我用AI两周就重写完了!”
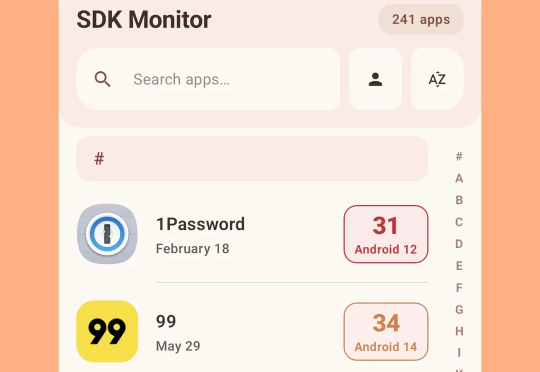
“废弃了7年的老Android项目,我用AI两周就重写完了!”大约 7 年前,我发布了一个名为 SDK Monitor 的小工具应用,用来监控设备上安装的所有应用使用的 targetSDK API 级别。当时正值 Google 开始强制推行 targetSDK 最低版本限制(现在要求至少是去年的版本),于是我的原始应用很快就变旧了。随着时间的推移,我甚至已经无法再打开 Android Studio 去维护它了——开发环境和技术体系早已焕然一新。
来自主题: AI资讯
9115 点击 2025-07-01 15:38