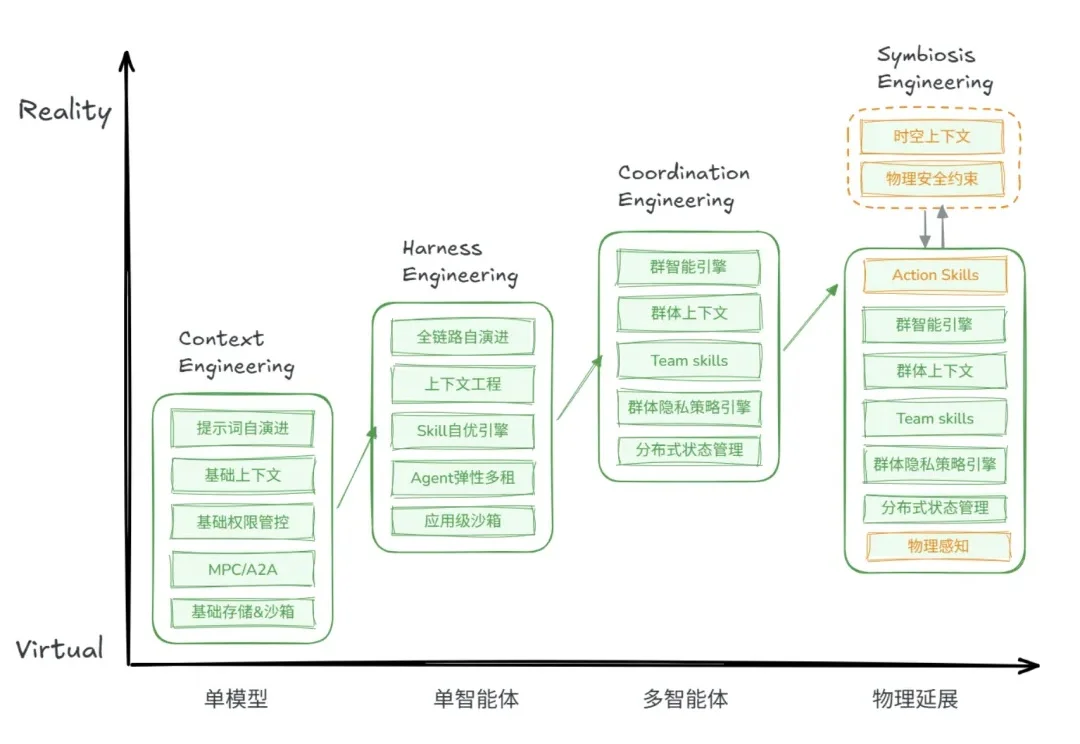
Agent终于长出了身体:Jiuwen Symbiosis背后的思考与实践
Agent终于长出了身体:Jiuwen Symbiosis背后的思考与实践如果你在三年前问AI圈:未来最强的AI长什么样?
来自主题: AI技术研报
9553 点击 2026-06-15 14:21
 搜索
搜索
如果你在三年前问AI圈:未来最强的AI长什么样?

周四晚上,我在床上举着 iPhone Air,在 Siri 对话框里打下了一个从来没问过的问题: Siri, what do you think of me?(Siri,你觉得我怎么样?)

近日,全球领先的具身自主科研智能基础设施提供商,深圳津渡生物医学科技有限公司(以下简称“津渡生科”)宣布完成近亿元A轮融资,本轮融资由高特佳投资领投,指数资本担任独家财务顾问。融资资金将重点用于深化物理AI(Physics-AI)底层架构研发、BioFord Agent科研智能体平台的迭代升级及全球市场布局拓展。
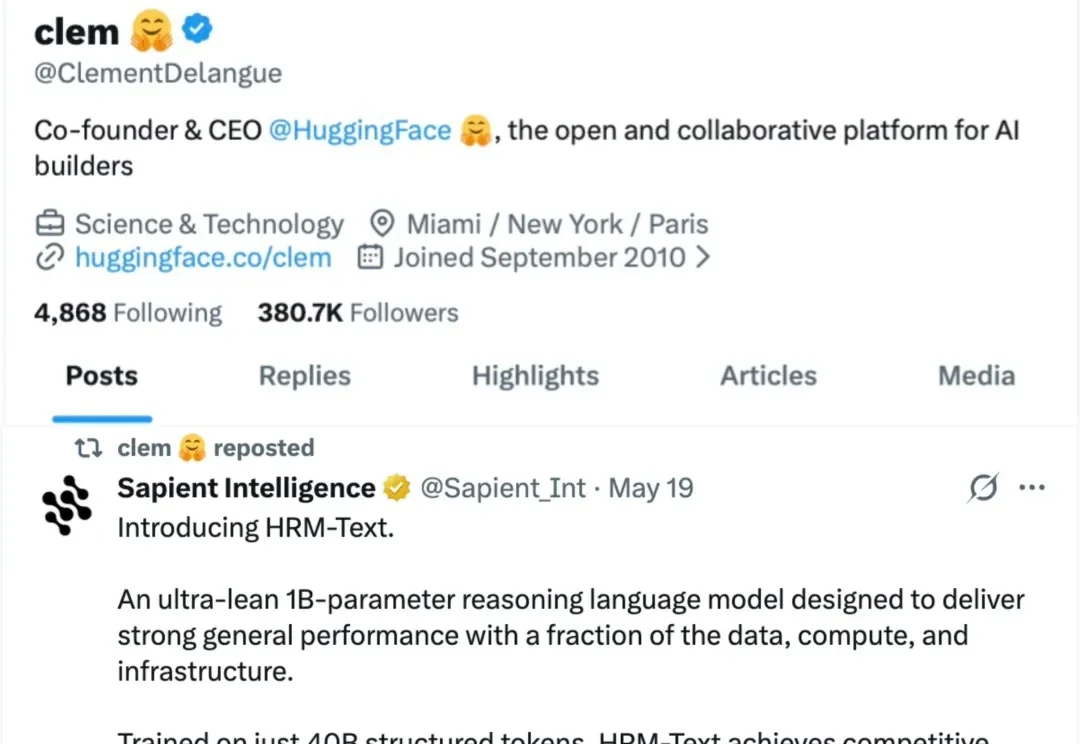
好家伙,这次不是模型圈自嗨。

近日,专注低功耗AI模型的初创公司Flourish Inc. 完成5亿美元融资。本次融资由GV、Lux Capital、Catalio Capital Management等知名投资机构及杰夫·贝索斯参与投资。本轮融资亦是2026年6月初全球规模最大的融资轮次之一。
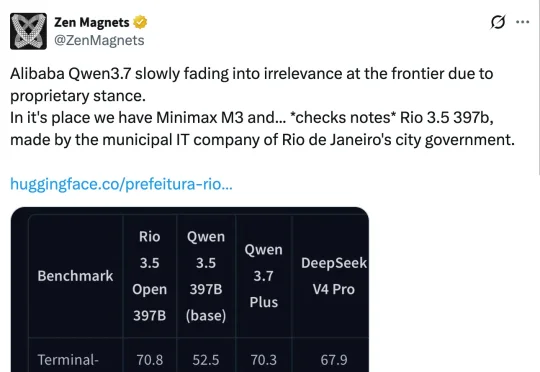
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。

Minerva 正式公开上线了他们的 AI 营销平台,同时宣布完成了这轮融资。投资方名单相当亮眼:The General Partnership、8VC、Lingotto Innovation、Topology Ventures,还有 NBA 官方投资部门 NBA Investments。与此同时,他们还公布了与 OpenAI 的深度合作关系,

The Information 周一报道称,Google 在数月测试这家芯片制造商的技术后,决定委托英特尔生产部分张量处理单元(TPU)。该媒体指出,由于台湾芯片制造商台积电的产能持续供不应求,英特尔正从 Google 等企业获得订单。

2026年6月,个人AI助手Town完成5500万美元A轮融资,由a16z领投,Forerunner、First Round、Conviction等机构跟投。在Agent赛道高度拥挤的背景下,这笔融资释放了一个明确信号
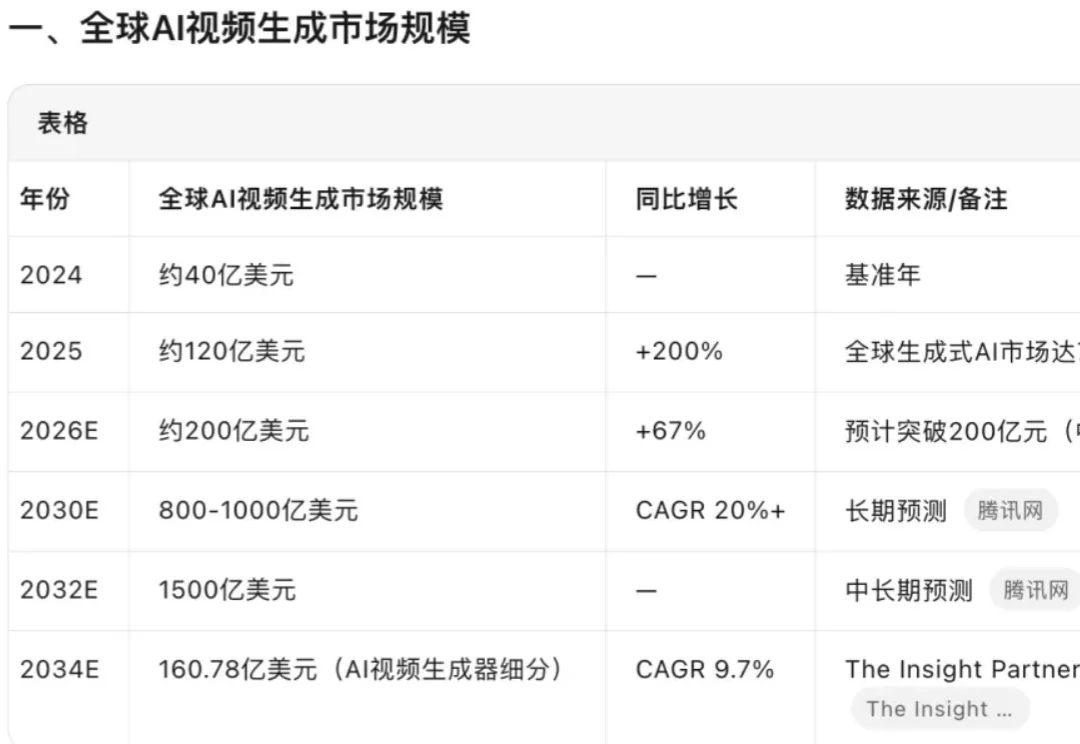
我最近专门调研了一下AI短视频🧐。发现市场规模是越来越大。