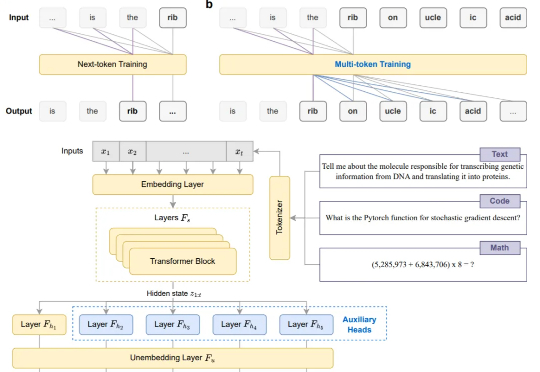
突破单token预测局限!南洋理工首次将多token预测引入微调,编程任务准确率提升11.67%
突破单token预测局限!南洋理工首次将多token预测引入微调,编程任务准确率提升11.67%告别Next-token,现在模型微调阶段就能直接多token预测!
来自主题: AI技术研报
9557 点击 2025-07-25 10:00
 搜索
搜索
告别Next-token,现在模型微调阶段就能直接多token预测!
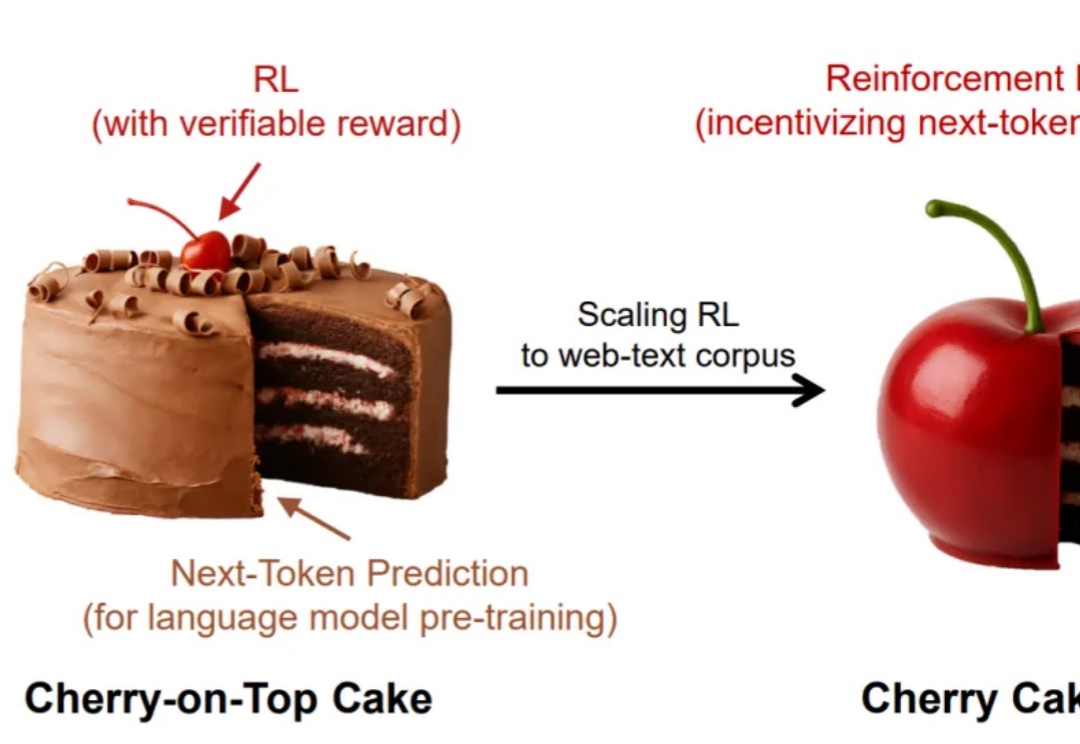
谁说强化学习只能是蛋糕上的樱桃,说不定,它也可以是整个蛋糕呢?
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。

研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。