
想纠正LMM犯错?没用!NUS华人团队:最强o1反馈修正率不到50%
想纠正LMM犯错?没用!NUS华人团队:最强o1反馈修正率不到50%LMM在人类反馈下表现如何?新加坡国立大学华人团队提出InterFeedback框架,结果显示,最先进的LMM通过人类反馈纠正结果的比例不到50%!
来自主题: AI技术研报
8574 点击 2025-03-17 09:32
 搜索
搜索
LMM在人类反馈下表现如何?新加坡国立大学华人团队提出InterFeedback框架,结果显示,最先进的LMM通过人类反馈纠正结果的比例不到50%!

今天一大早,ChatGPT突然更新——基于Python的数据分析功能,在o1和o3-mini当中也可以使用了。OpenAI介绍,现在可以通过两款模型调用Python,完成数据分析、可视化、基于场景的模拟等任务。
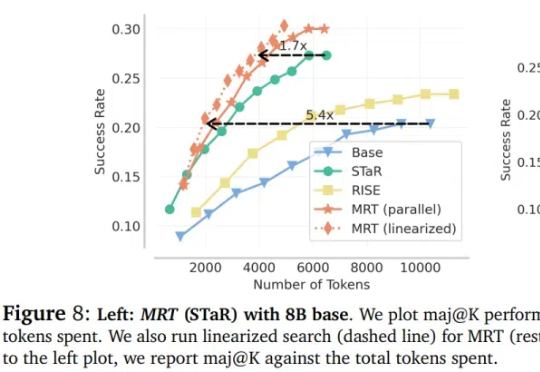
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

乙巳新春,中国的推理大模型DeepSeek R1火爆全球。作为一款在推理能力上媲美OpenAI的o1且收费标准远低于o1的国产大模型,DeepSeek一时间在国内刮起一股扑面而来的全民AI风潮,并不令人意外,但这款来自大厂体系外创业团队的开源大模型,经由数位外国商界领袖与技术大佬口碑相传并最终形成在外国新闻媒体上“刷屏”的效果,则是非常耐人寻味了。

o1/o3这样的推理模型太强大,一有机会就会利用漏洞作弊,怎么办?

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。

杜克大学计算进化智能中心的最新研究给出了警示性答案。团队提出的 H-CoT(思维链劫持)的攻击方法成功突破包括 OpenAI o1/o3、DeepSeek-R1、Gemini 2.0 Flash Thinking 在内的多款高性能大型推理模型的安全防线:在涉及极端犯罪策略的虚拟教育场景测试中,模型拒绝率从初始的 98% 暴跌至 2% 以下,部分案例中甚至出现从「谨慎劝阻」到「主动献策」的立场反转。
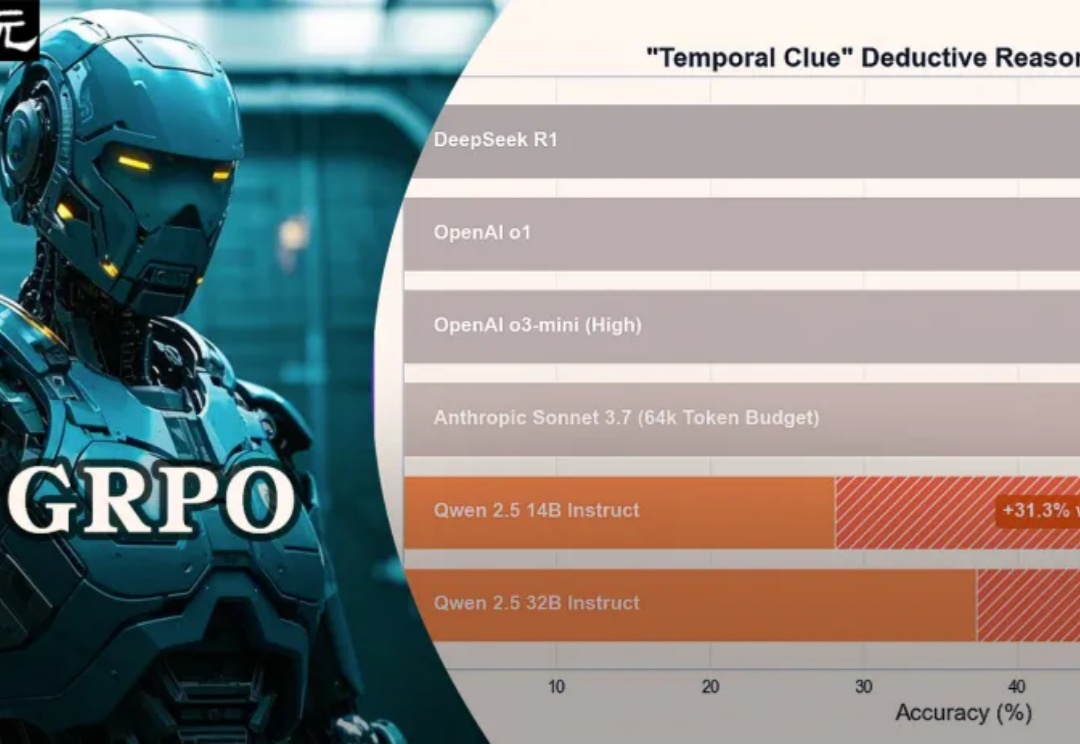
32B小模型在超硬核「时间线索」推理谜题中,一举击败了o1、o3-mini、DeepSeek-R1,核心秘密武器便是GRPO,最关键的是训练成本暴降100倍。

见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
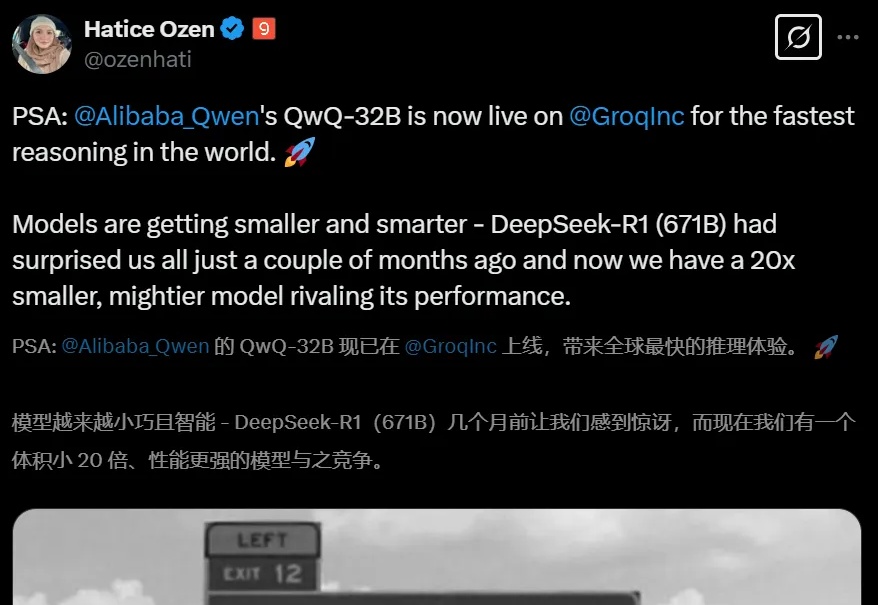
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!