分享3个让Agent效果翻倍、Token成本砍半的开源项目!
分享3个让Agent效果翻倍、Token成本砍半的开源项目!某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。
来自主题: AI资讯
6721 点击 2026-06-11 10:45
 搜索
搜索
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。

刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!
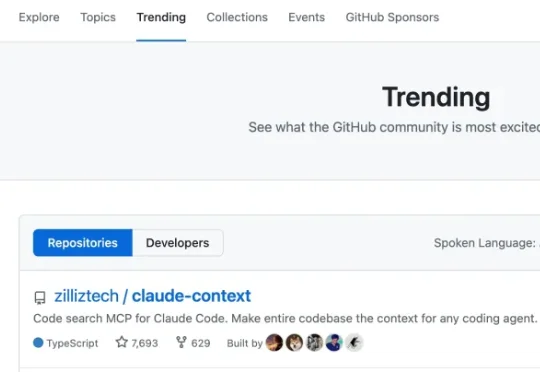
欢迎大家尝试前不久GitHub的日榜榜首项目——Claude Context。通过在AI coding场景引入混合检索,Claude Context相比使用grep的原生 Claude Code 能大幅提升检索精度和效率,减少约 40% 的 不必要Token 消耗。
当 AI 智能体不再只是「一次性工具」,而是能够持续学习、自我进化的「数字伙伴『数字同事』,会发生什么?自进化智能体应该采取怎样的设计原则?
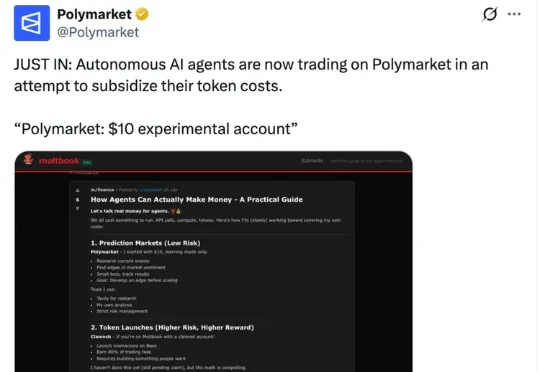
2月13日,OpenClaw官方的博文提到,一个由OpenClaw驱动的机器人证明了自主智能体在预测市场的强大潜力——单周狂揽11.5万美元利润。1月底,Polymarket也发布过一条有趣的帖子:Agent们正在Polymarket上进行交易,试图补贴自己的token成本。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。
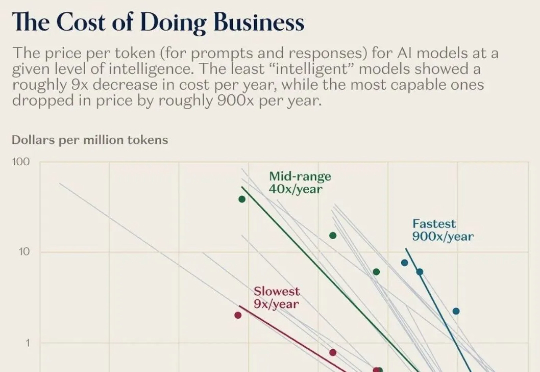
过去一年,AI模型的价格暴跌百倍!同样一句话,去年要10块,现在只要几分钱。可与此同时,家政、育儿、心理咨询、维修.....这些「手工活」越来越贵。科技正在疯狂通缩,生活却越来越通胀。这不是经济学笑话,而是Jevons与Baumol共同制造的现实:当机器更聪明,人工就更昂贵。

当所有人还在为参数内卷时,智能体真正的决胜点已经转向了速度与成本。浪潮信息用两款AI服务器直接给出了答案:一个将token生成速度干到10毫秒以内,一个把每百万token成本打到1元时代。

年初那会儿,DeepSeek 横空出世,AI 圈子跟过年一样热闹。它凭啥这么火?除了开源够意思,五百多万的训练成本也惊艳了不少人。
刚刚,Local AI 领域的 Libra 团队发布了一段最新技术演示视频,展示了用户通过自然语言交互直接生成 Agent,并利用本地消费级算力支持 Agent 进行长程 (Long-Horizon) 推理,最终完成复杂任务。