
千帧长视频时代到来!MIT全新扩散算法让任意模型突破时长极限
千帧长视频时代到来!MIT全新扩散算法让任意模型突破时长极限进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
来自主题: AI技术研报
8516 点击 2025-02-26 13:39
 搜索
搜索
进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
谷歌首席科学家Jeff Dean与Transformer作者Noam Shazeer在一场访谈中不仅揭秘了让模型速度提升三倍的低精度计算技术,分享了「猫神经元」等早期AI突破的背后故事,还大胆畅想了AI处理万亿级别Token、实现「1000万倍工程师」的可能性。
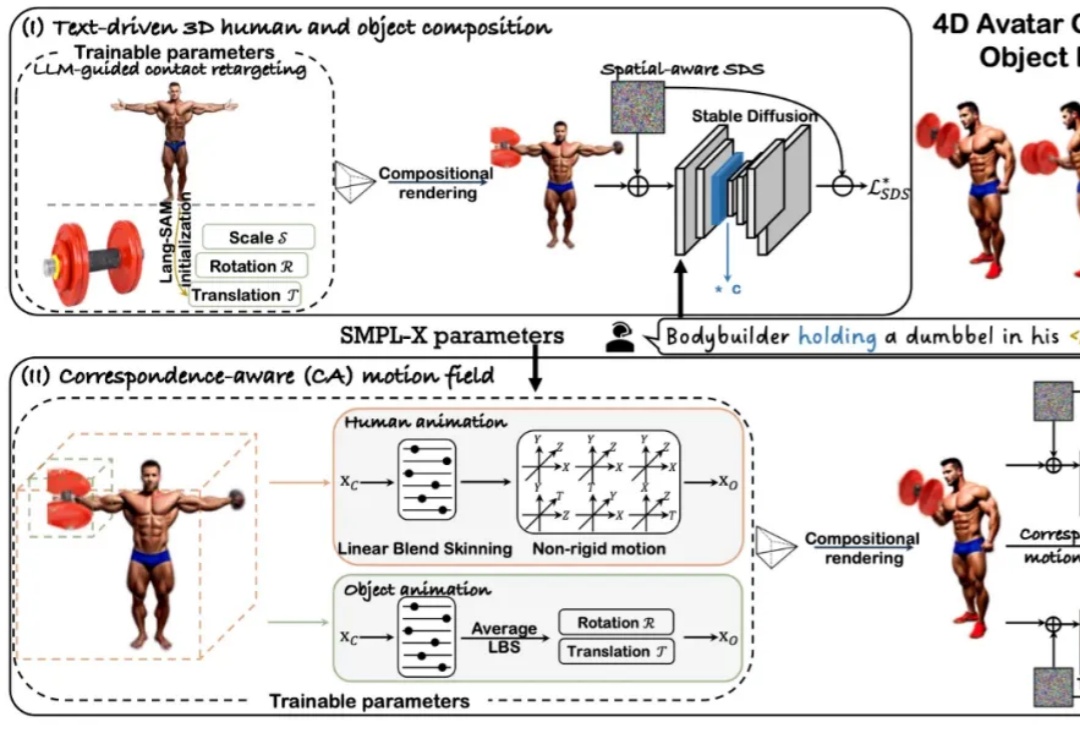
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。
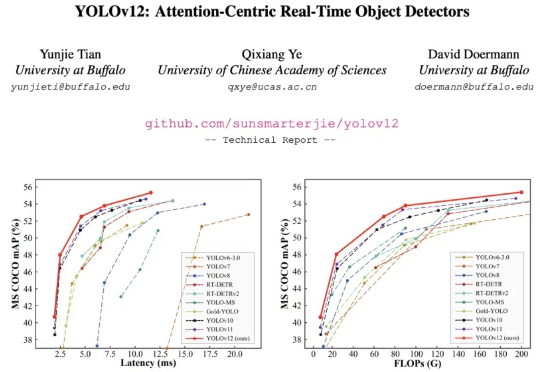
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。

Transformer论文八位作者之一Llion Jones创立的Sakana AI发布重磅成果——全球首个「AI CUDA工程师」!它能将PyTorch代码自动转换为高度优化的CUDA内核,速度比PyTorch原生实现快10-100倍。
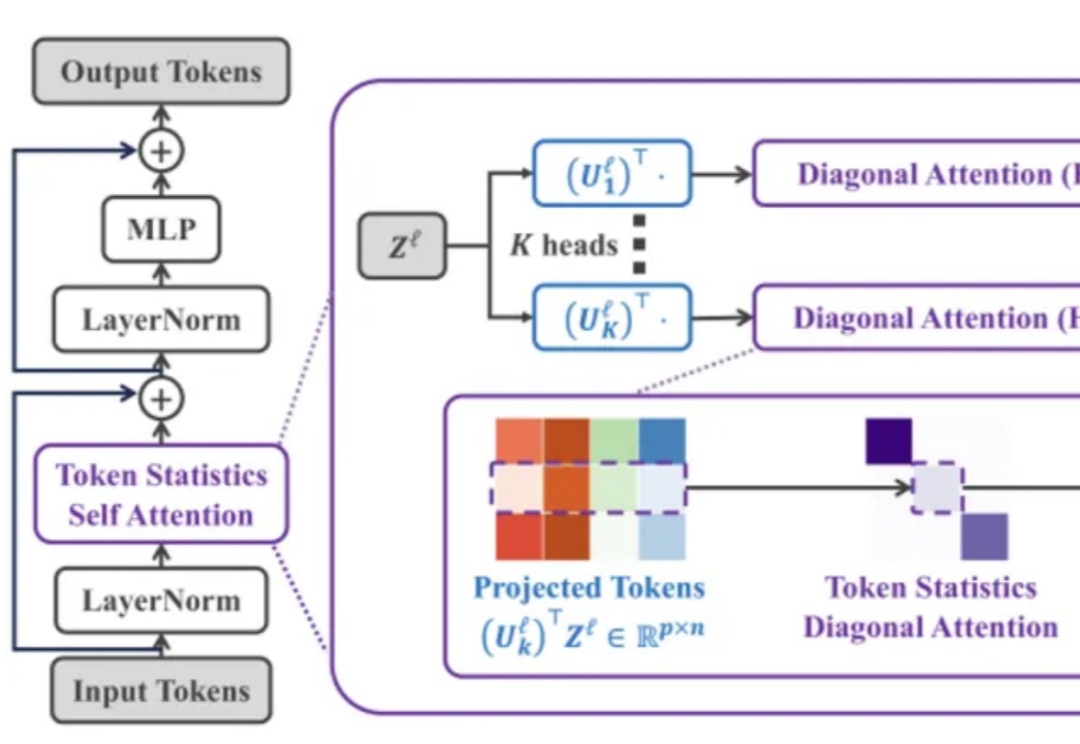
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,

人类智慧的一大特征是能够分步骤创造复杂作品,例如绘画、手工艺和烹饪等,这些过程体现了逻辑与美学的融合。
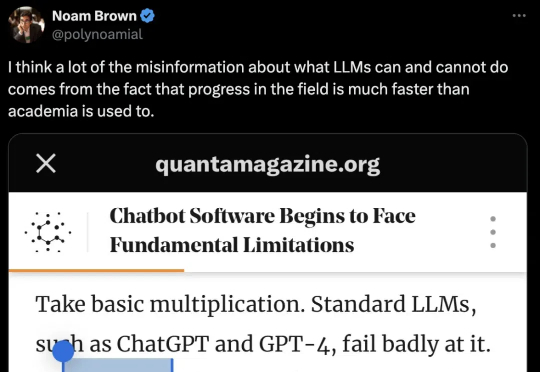
一篇报道,在AI圈掀起轩然大波。文中引用了近2年前的论文直击大模型死穴——Transformer触及天花板,却引来OpenAI研究科学家的紧急回应。谁能想到,一篇于2023年发表的LLM论文,竟然在一年半之后又「火」了。

SANA 1.5是一种高效可扩展的线性扩散Transformer,针对文本生成图像任务进行了三项创新:高效的模型增长策略、深度剪枝和推理时扩展策略。这些创新不仅大幅降低了训练和推理成本,还在生成质量上达到了最先进的水平。