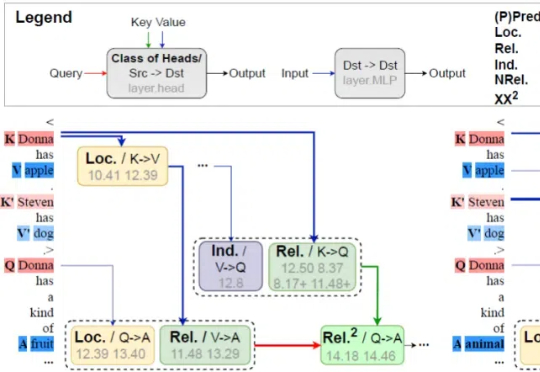
大模型会组合关系推理吗?打开黑盒,窥探Transformer脑回路
大模型会组合关系推理吗?打开黑盒,窥探Transformer脑回路本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn
来自主题: AI技术研报
5900 点击 2025-02-06 15:30
 搜索
搜索
本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn

研究者提出了FAST,一种高效的动作Tokenizer。通过结合离散余弦变换(DCT)和字节对编码(BPE),FAST显著缩短了训练时间,并且能高效地学习和执行复杂任务,标志着机器人自回归Transformer训练的一个重要突破。
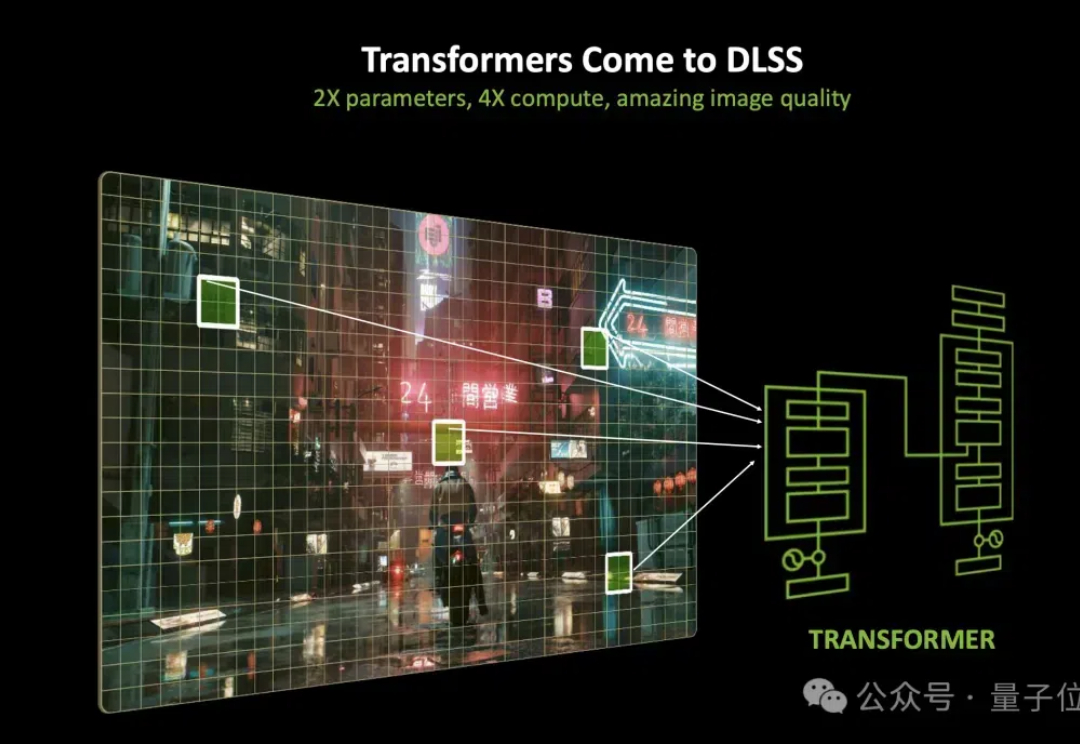
现在,打个游戏都用上Transformer了?! 老黄的DLSS进行了一波大升级,换上了基于Transformer的新大脑。 用上新模型之后,光线重建和超分辨率,效果都变得更细腻了。

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。

Stability AI推出3D重建方法:2D图像秒变3D,还可以交互式实时编辑。新方法的原理、代码、权重、数据全公开,而且许可证宽松,可以商用。新方法采用点扩展模型生成稀疏点云,之后通过Transformer主干网络,同时处理生成的点云数据和输入图像生成网格。以后,人人都能轻松上手3D模型设计。

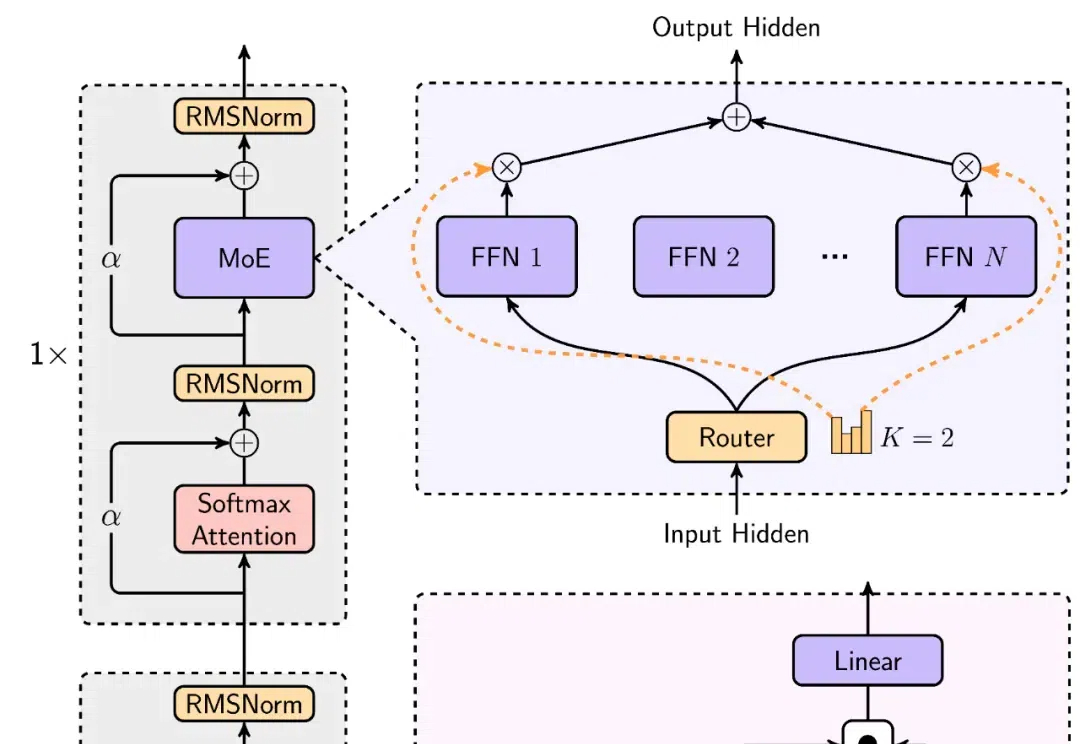
正如论文一作所说,「新架构 Titans 既比 Transformer 和现代线性 RNN 更有效,也比 GPT-4 等超大型模型性能更强。」
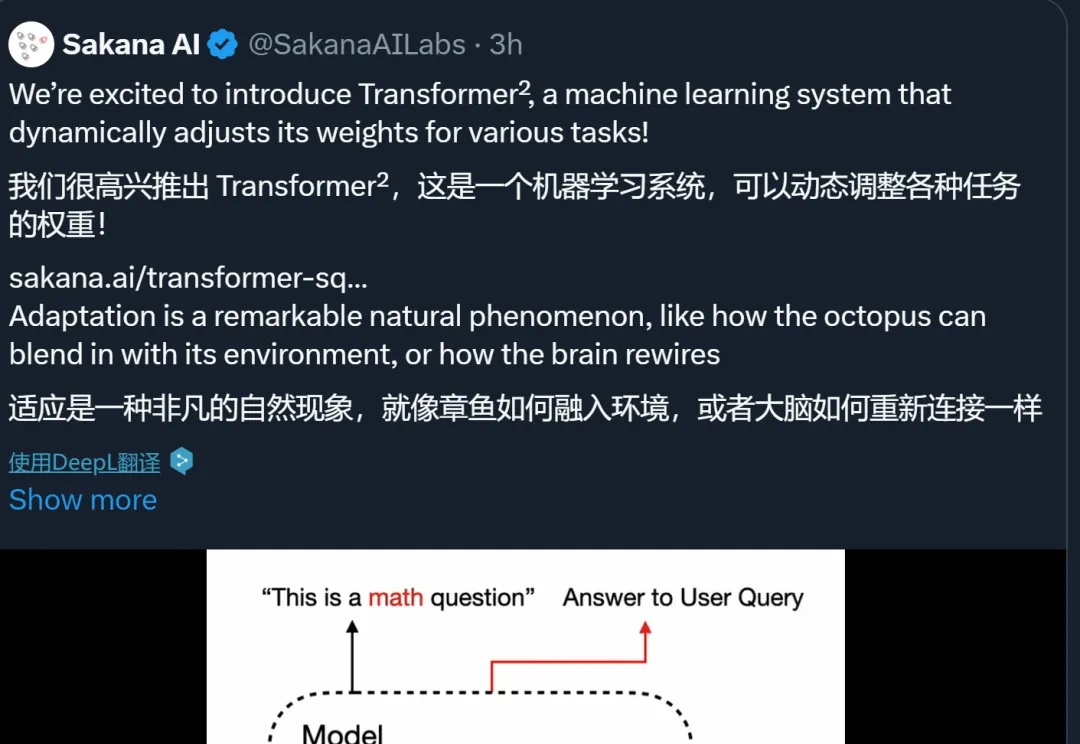
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman
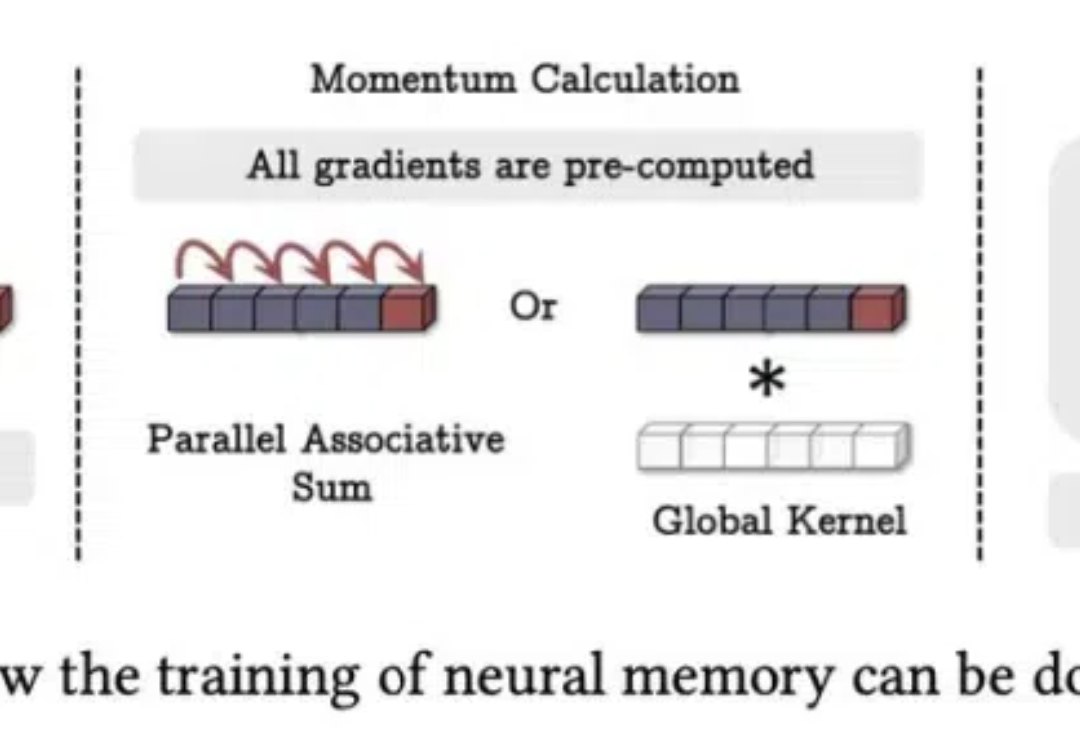
想挑战 Transformer 的新架构有很多,来自谷歌的“正统”继承者 Titan 架构更受关注。
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。