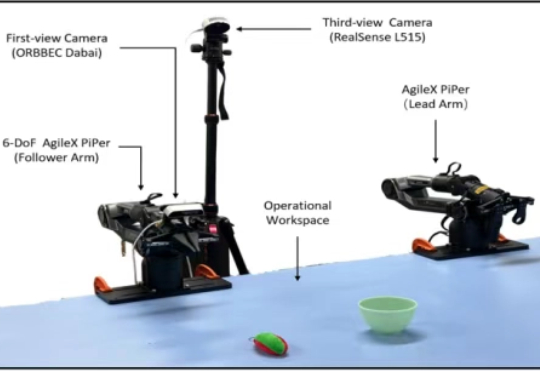
VLA 推理新范式!一致性模型 CEED-VLA 实现四倍加速!
VLA 推理新范式!一致性模型 CEED-VLA 实现四倍加速!近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。
来自主题: AI技术研报
8173 点击 2025-07-14 11:12
 搜索
搜索
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。

两位清华校友,在OpenAI发布最新研究—— 生成图像,但速度是扩散模型的50倍。 路橙、宋飏再次简化了一致性模型,仅用两步采样,就能使生成质量与扩散模型相媲美。

多项改进实现规模空前的连续时间一致性模型。