Scaling Law没死!Gemini核心大佬爆料,谷歌已有颠覆性密钥
Scaling Law没死!Gemini核心大佬爆料,谷歌已有颠覆性密钥谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!
来自主题: AI资讯
8901 点击 2025-12-20 10:13
 搜索
搜索
谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!

周五凌晨,OpenAI 发布 GPT-5.2-Codex,这是迄今为止最先进的智能体编码模型,专为复杂的实际软件工程而设计。GPT-5.2-Codex 是 GPT-5.2 的升级版本,提高了指令遵循能力、对长远语境的理解能力,它针对 Codex 中的智能体编码进行了进一步优化,包括通过上下文压缩改进长期工作。
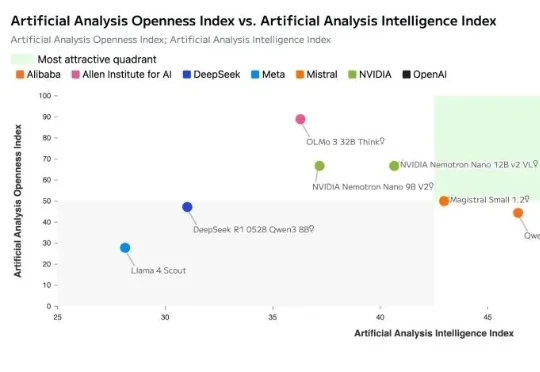
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。

正如奥特曼执意打造硬件,试图打破手机屏束缚,要让 AI 感受物理世界;Looki 的诞生也源于同样的渴望:补齐大模型「感官智能」的最后拼图,将现实场景实时转化为上下文,驱动人机交互从「被动问答」进化为「主动共鸣」。
原生工具调用、128K上下文,图文创作仍有短板。

最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。
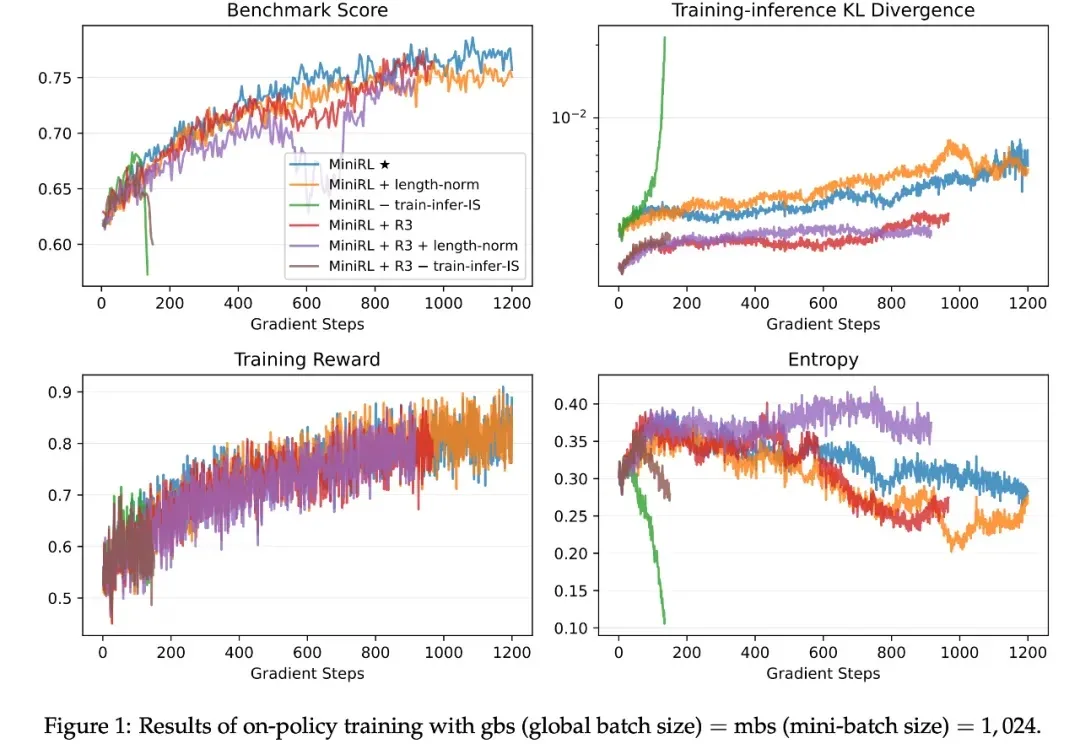
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。

随着大语言模型与开发工具链的深度融合,命令行终端正被重塑为开发者的AI协作界面。本文以 Google gemini-cli 为范本,通过源码解构,系统性分析其 Agent 内核、ReAct 工作流、工具调用与上下文管理等核心模块的实现原理。为希望构建终端 Agent 的开发者,提供工程实现的系统化参考。