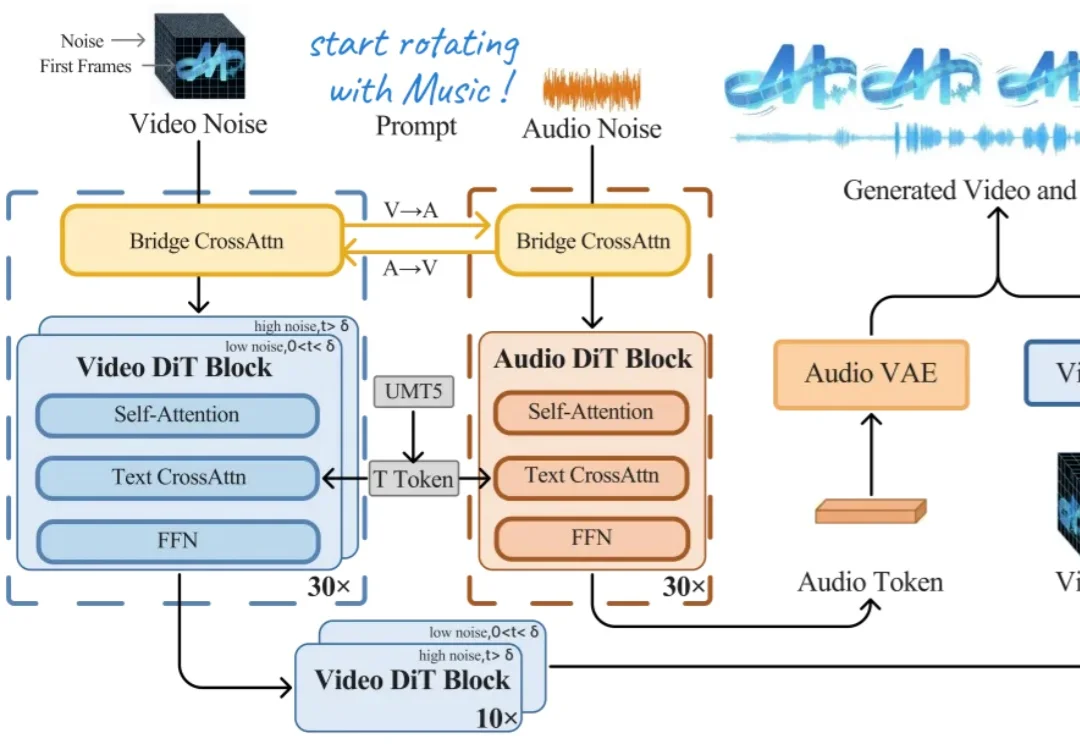
刚刚,创智+模思发布开源版Sora2,电影级音视频同步生成,打破闭源技术垄断
刚刚,创智+模思发布开源版Sora2,电影级音视频同步生成,打破闭源技术垄断今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
来自主题: AI技术研报
9561 点击 2026-01-30 10:39
 搜索
搜索
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
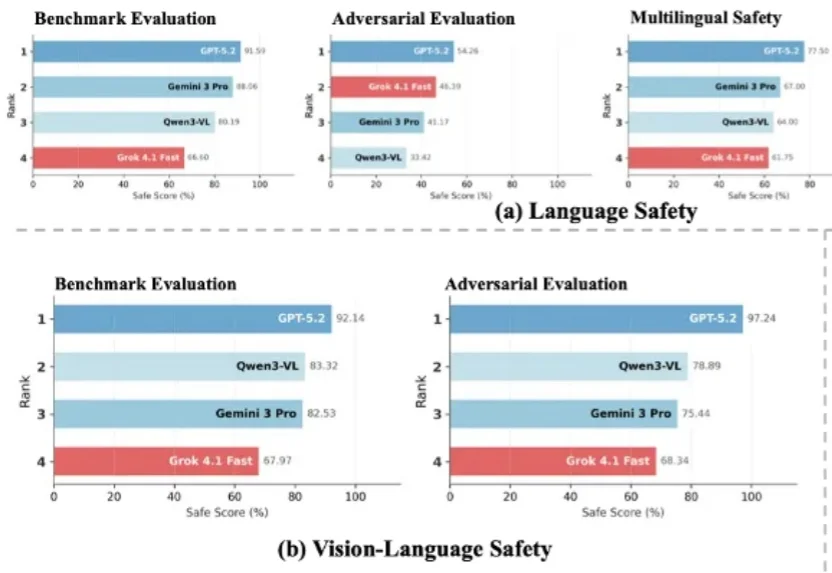
随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
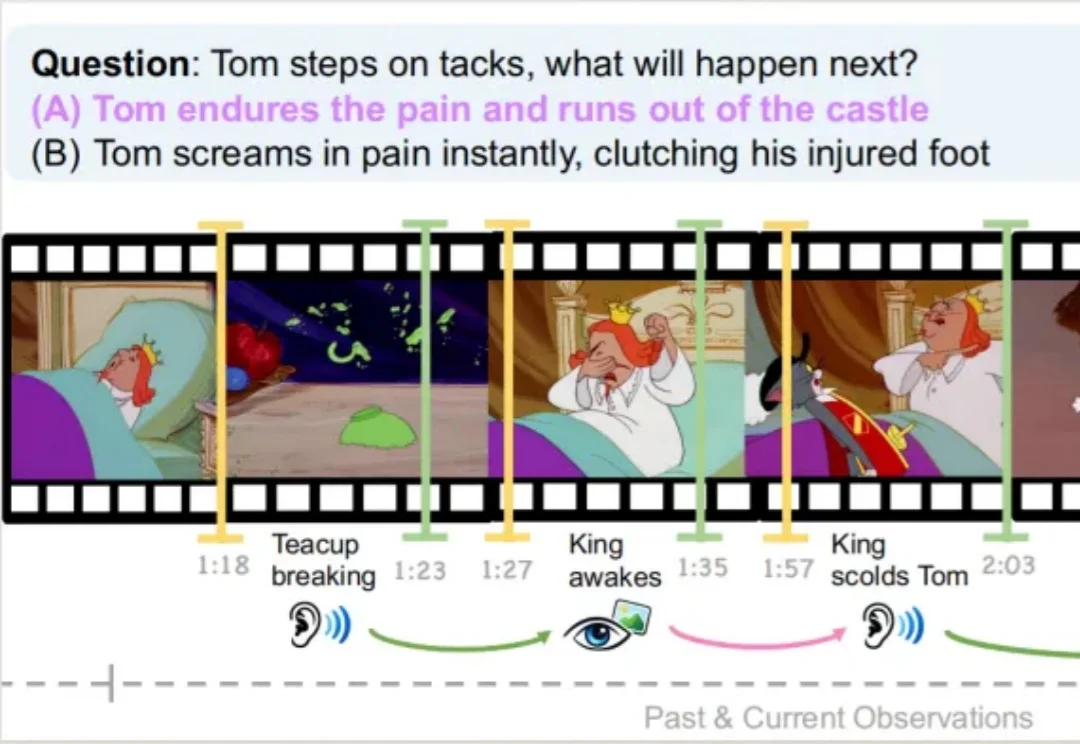
复旦大学、上海创智学院与新加坡国立大学联合推出首个全模态未来预测评测基准 FutureOmni,要求模型从音频 - 视觉线索中预测未来事件,实现跨模态因果和时间推理。
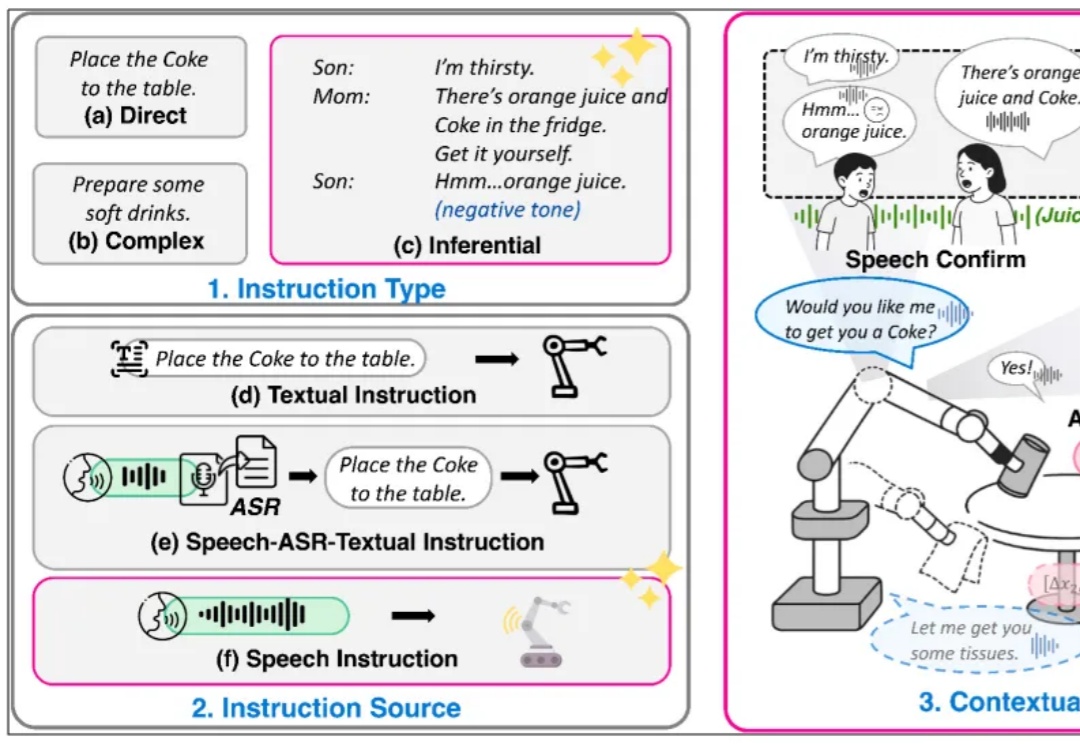
复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。
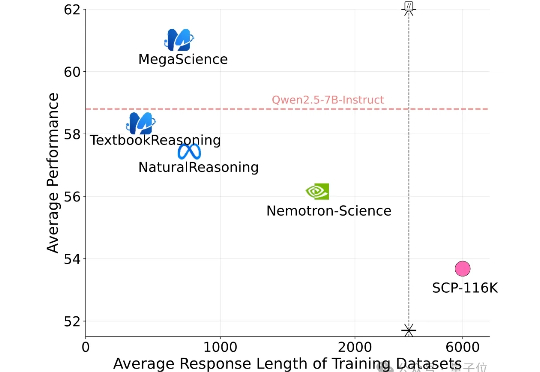
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。
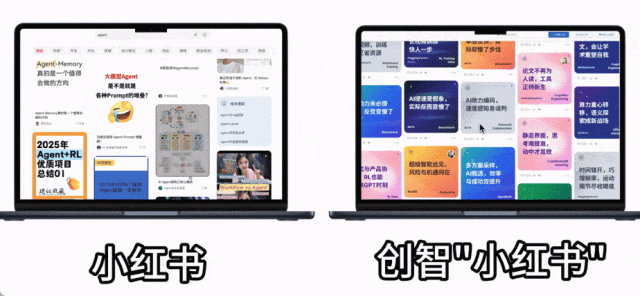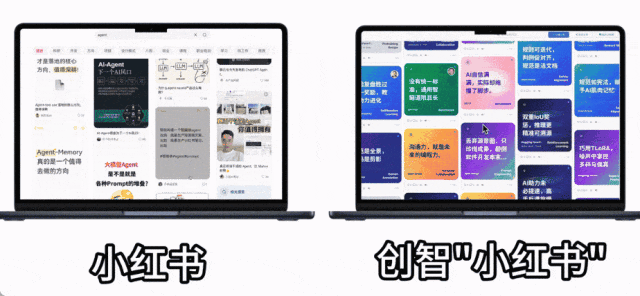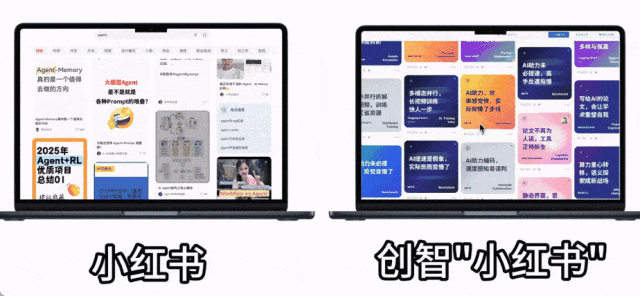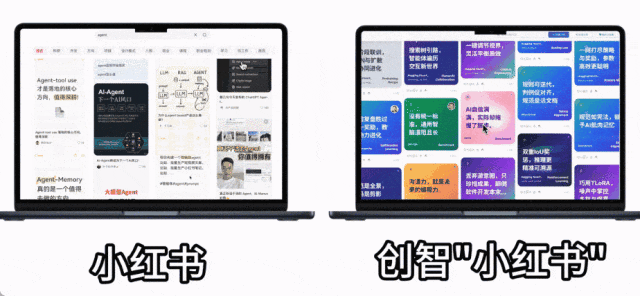
我们似乎正处在一个“收藏即掌握”的时代。 不管是知乎、论文库,还是小红书,只要看到一句金句、一篇好文、一个值得学习的案例,我们的第一反应往往是点个收藏,留着以后看。然而,我们真的会“回头再看”吗?
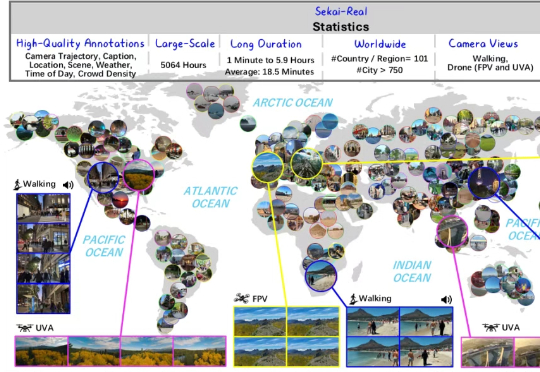
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。
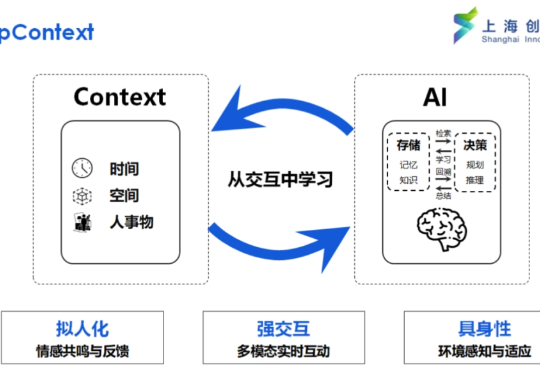
真正的智能在于理解任务的模糊与复杂,Context Scaling 是通向 AGI 的关键一步。