多模态DeepResearch,成了!
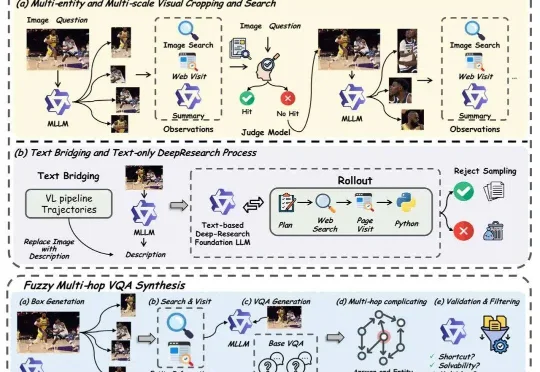
多模态DeepResearch,成了!DeepResearch 的价值在于把「查资料」变成「做研究」:不是搜到一条就回答,而是会连续多轮地提出问题、去不同地方找证据、互相对照核实、再把信息整理成结构清晰的结论。这样做能显著降低「凭感觉瞎编
来自主题: AI技术研报
8354 点击 2026-02-24 15:41
 搜索
搜索
DeepResearch 的价值在于把「查资料」变成「做研究」:不是搜到一条就回答,而是会连续多轮地提出问题、去不同地方找证据、互相对照核实、再把信息整理成结构清晰的结论。这样做能显著降低「凭感觉瞎编

今天,就是这个小破公众号的3周年了。其实很多时候不是太想也不太敢写这样的文章。因为总是会感觉会让人显得很有登味。但,这一次春节回家,跟很多亲戚朋友聊了聊,还是能感觉到信息的参差。
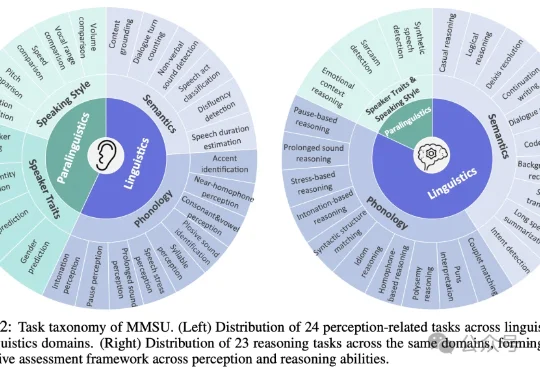
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?

我正对着镜子站立,举起一只手。在我的视野中,这只手出现在镜子画面的左侧。 请问在现实中,我举起的是哪只手? 答案应该是:左手。 一道堪比「9.11 > 9.8」的 AI 陷阱题。 前两天,我拿它测了一

奥特曼又又又又口出狂言了。在印度 Express Adda 的论坛上,Sam Altman 聊了很多 AI 话题,从 AGI 到中美 AI 竞争,再到数据中心用水问题。但最火的那段,是他回应 AI 能耗批评时说的:「人们总谈训练 AI 模型需要多少能源……但训练人类也需要大量能源,得花 20 年时间,消耗那么多食物,才能变聪明。」

作者 | 高允毅 很多人知道,Transformer 是谷歌发明的。但 ChatGPT,却不是谷歌做出来的。这件事,在过去几年,几乎成了硅谷最大的“遗憾注脚”。 但如果真正走进今天的 Google D

马上春节假期都结束了,不知道大家有没有人被家里催婚 😭 我这几天一直躺在屋里,为了躲避惨无人道的亲戚催婚,睡得昏天暗地,睡觉、刷抖音、刷 X、刷小红书、吃饭、睡觉,闭环了。 就在昨天,我日常刷抖音的时
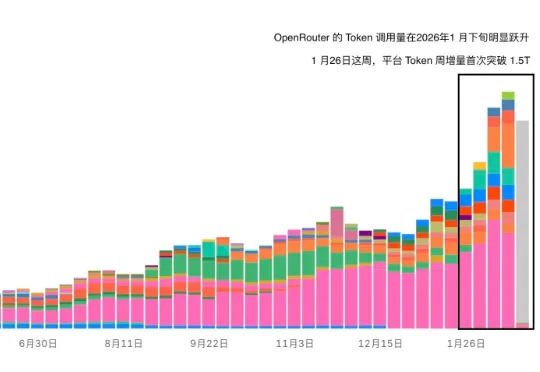
作为目前全球最主要的大模型 API 聚合网关之一,OpenRouter 的 Token 调用量在 2026 年 1 月下旬出现了明显跃升。自 1 月 26 日当周开始,平台 Token 周增量首次突破 1.5T,这一幅度在过去的调用曲线中并不常见。时间点同样值得玩味——这一轮增长几乎与 OpenClaw 的迅速传播高度重合。人们开始发现,OpenClaw 简直就是 Token 碎纸机。

诺奖得主Hassabis,刚刚给AGI一个新定义——爱因斯坦测试!能在4年内推导出1915年广义相对论的,才算真正的AGI。马斯克立即来反驳了:人类集体都没独立重现相对论,要是AI真能做到,那就不是AGI,而是「超神」了。但无可否认:AGI,真的超近了

「自然语言就是新的编程语言。」这句话在过去一年里被无数人奉为圭臬。特斯拉前 AI 总监 Andrej Karpathy 带火的 「Vibe Coding」(氛围编程)更是让这种狂热达到了顶峰——你不需要懂语法,不需要管实现,只要对着 AI 喊出需求,然后 Check 一下感觉(Vibe)对不对就行了。