
智源开源EditScore:为图像编辑解锁在线强化学习的无限可能
智源开源EditScore:为图像编辑解锁在线强化学习的无限可能随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。
来自主题: AI技术研报
10885 点击 2025-10-23 12:28
 搜索
搜索
随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。

整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。
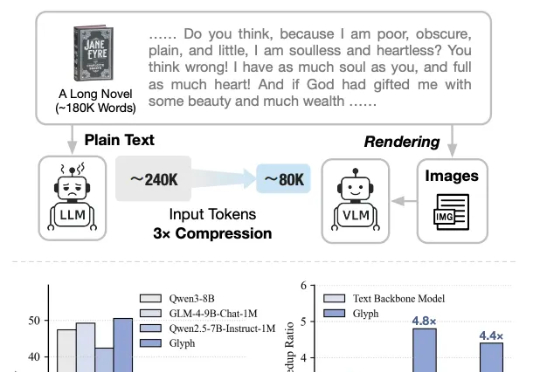
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:

虽然浏览器 AI agent 的概念听起来很美好,但实际构建这样的系统却面临巨大挑战。这正是 Kernel 要解决的核心问题。我发现很多开发者想要构建 AI agent,但却在基础设施层面遇到了各种障碍:性能不稳定、运行时间不可靠、定价不合理、身份认证复杂、权限管理混乱,以及一个本来就不是为 agent 设计的互联网世界。

刚刚,这个开源的VLA一站式平台,不仅让UR5e真机实现了100%成功率,还在五大仿真环境中全面领先,最高性能提升高达46%,而且还支持RTX 4090训练!最近,由Dexmal 原力灵机重磅开源的Dexbotic,则构建了一个「VLA统一平台」。Dexbotic作为具身智能VLA模型一站式科研服务平台,可以为VLA科研提供基础设施,加速研究效率。
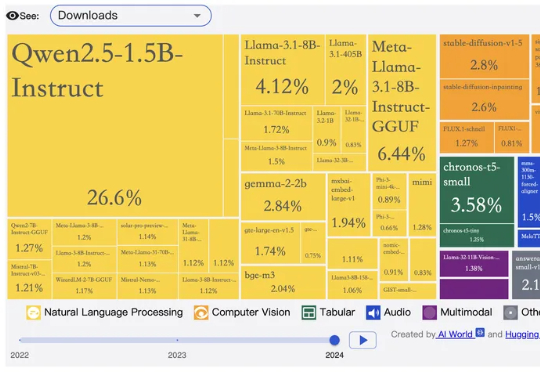
美国 AI 圈开始出现“担心中国开源断供”的苗头了吗?10 月 20 日,在专注于开源模型讨论、拥有 55 万成员的 Reddit 分论坛“r/LocalLLaMA”上,一位网友发布了一则“当中国公司停止提供开源模型时会发生什么?”的提问,并表达了假如中国模型逐渐闭源或开始收费该怎么办的担忧。
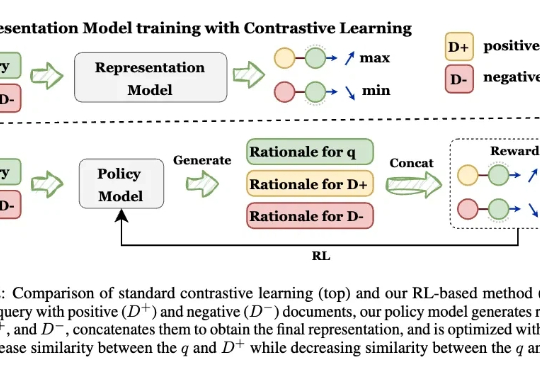
让模型先解释,再学Embedding! 来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
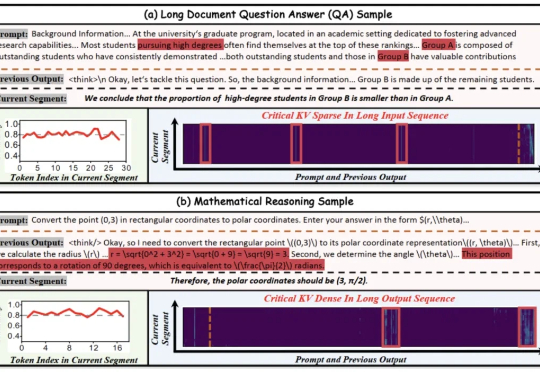
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。

传闻许久的 OpenAI AI Agent 浏览器,如今这个靴子终于正式落地。但 AI 浏览器已经是巨头新贵正在不断涌入的赛道,OpenAI 还未正式下场,就已经有了十足的火药味:预热推文评论区最高赞的评论,就是一名用户表示自己已经卸载了 Chrome,等待 Atlas,颇有点「打扫卫生再请客」的感觉。

美国签证体系,尤其在科技人才领域,长期被诟病为成本高、周期长、透明度低。前微软科学家Priyanka Kulkarni创办Casium,尝试用AI改造签证服务,把3–6个月的材料准备缩至10个工作日左右;部分案例不到1个月即可入职。