
推理AI致命弱点,大模型变「杠精」!被带偏后死不悔改
推理AI致命弱点,大模型变「杠精」!被带偏后死不悔改DeepMind新研究揭示了当与推理无关的想法,被直接注入到模型的推理过程中时,它们却难以恢复,而且越大的模型越难恢复。
来自主题: AI技术研报
9367 点击 2025-07-04 10:36
 搜索
搜索
DeepMind新研究揭示了当与推理无关的想法,被直接注入到模型的推理过程中时,它们却难以恢复,而且越大的模型越难恢复。
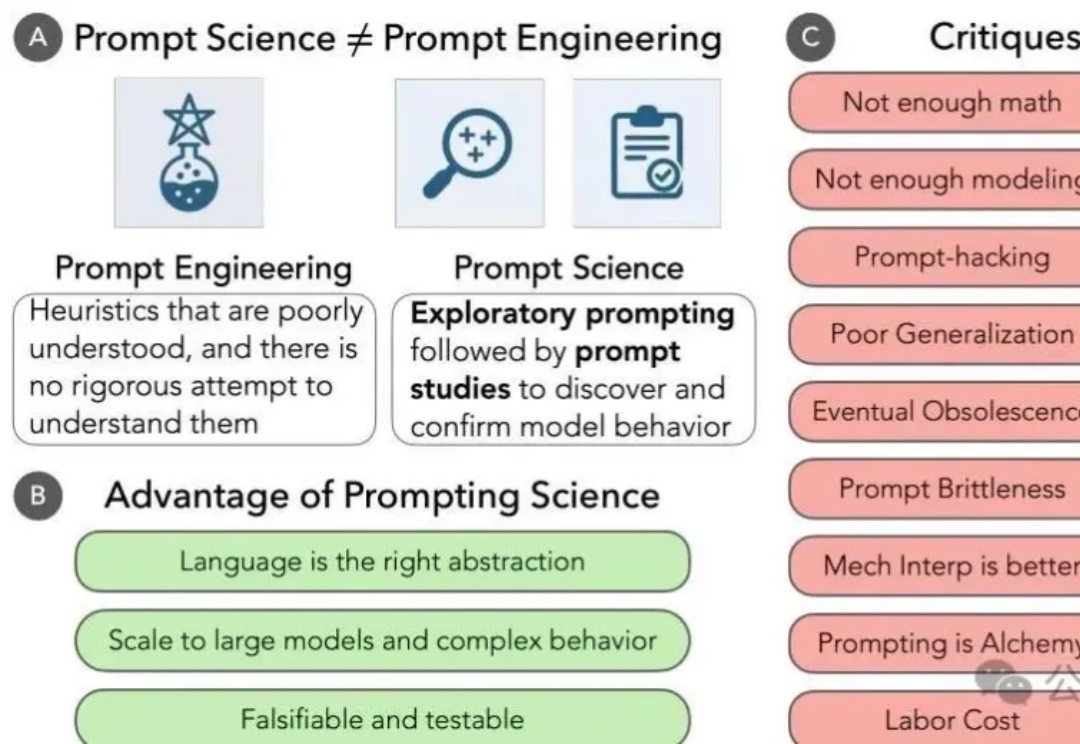
最近网上出现了一些很有趣的声音——"提示词已死"、"写提示词把自己写死了",这些文章认为随着模型变得越来越智能,精心设计提示词的时代已经过去了。但芝加哥大学的最新研究却给出了完全相反的结论:prompt不仅没有死,反而是理解大模型最重要的科学工具。
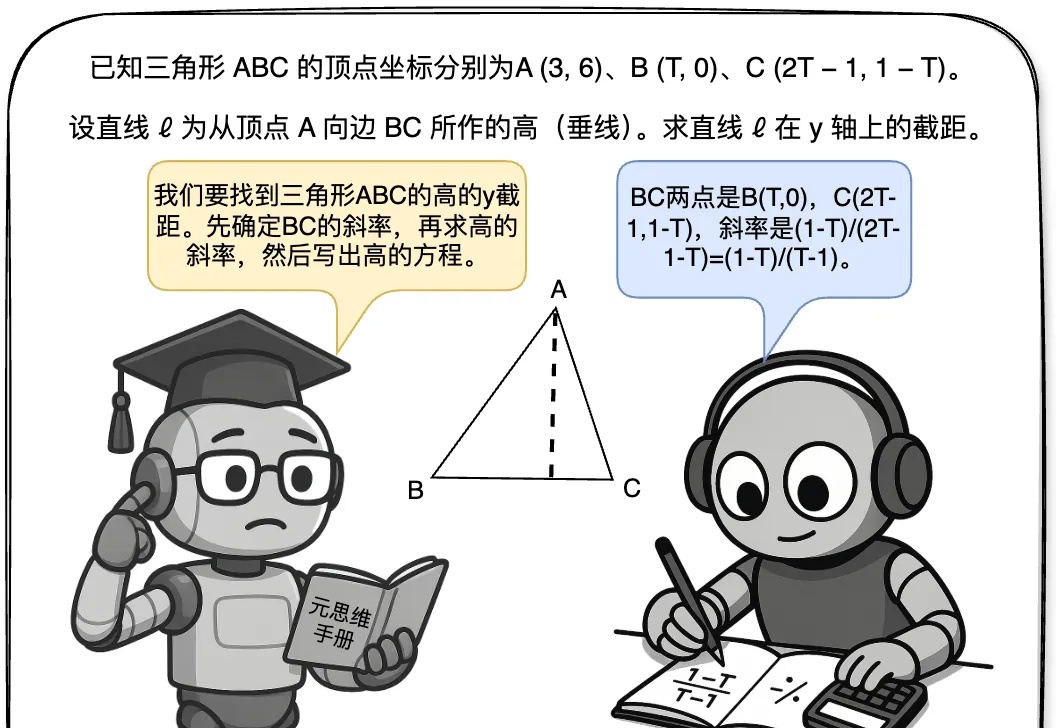
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。

就在刚刚,Ilya出现了!他大义凛然发文,自封为SSI唯一CEO,而Daniel Levy将担任总裁。要实现SSI的梦想,多少钱都不卖。
在 AI 工具风靡开发圈之前,一批经验丰富的资深程序员,对它们始终保持警惕。这些人,包括 Flask 作者 Armin Ronacher(17 年开发经验)、PSPDFKit 创始人 Peter Steinberger(17 年 iOS 和 macOS 开发经验),以及 Django 联合作者 Simon Willison(25 年编程经验)。然而,就在今年,他们的看法都发生了根本转变。

AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。

离谱! 一群AI初创公司竟然集体控诉:我们被一个印度老哥骗了。这个名叫Soham Parekh的人,在隐瞒真实情况下进行远程兼职,最多一次打了五份工。

曾几何时,用文字生成图像已经变得像用笔作画一样稀松平常。

在这个万物皆可AI的时代,教育自然也不例外。在智能化、个性化学习体验等多重需求的驱动下,人工智能与教育行业正在进行一场盛大的双向奔赴。

MIT最新研究让LLM直接操控宇宙飞船进行太空追逐挑战赛:ChatGPT少量微调即获第二,开源Llama更胜一筹,凭提示词精准追踪卫星、节省燃料,更是0%失败率,验证AI小数据高效与自主航天可行,为未来的太空漫游铺路。