
AI进入组织,为什么选择飞书?
AI进入组织,为什么选择飞书?2026年,飞书新增客户中有九成同时采购飞书AI产品。
来自主题: AI资讯
8754 点击 2026-06-18 10:16
 搜索
搜索
2026年,飞书新增客户中有九成同时采购飞书AI产品。
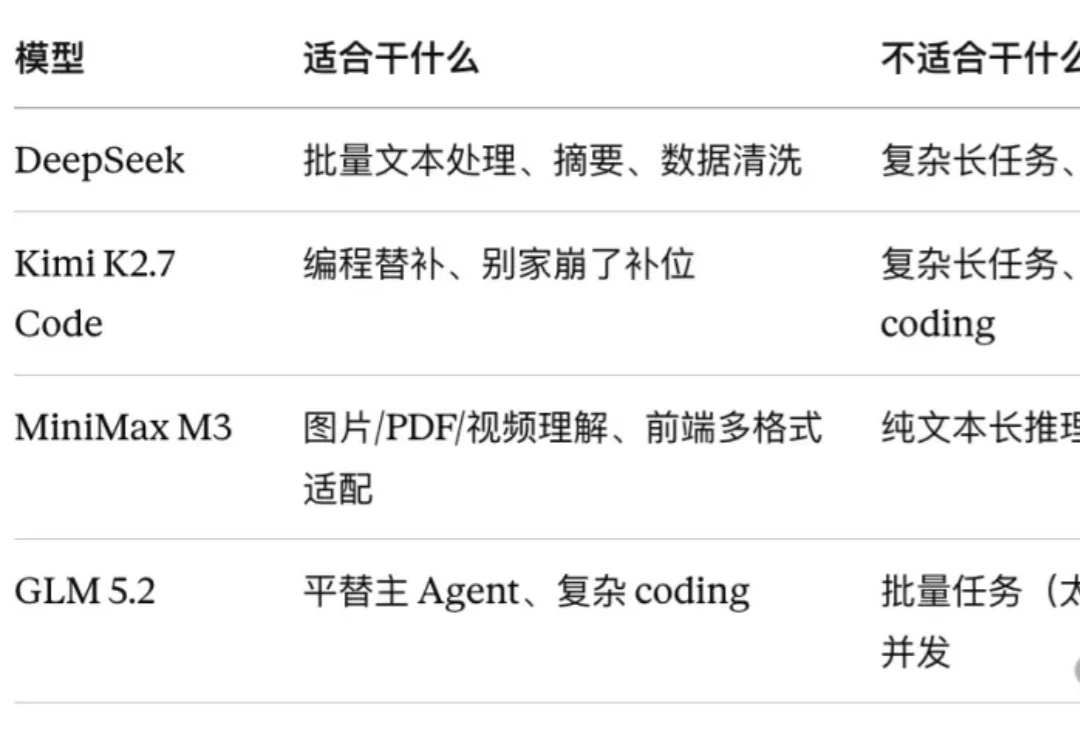
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。

究竟谁将率先点燃AI游戏这把火?
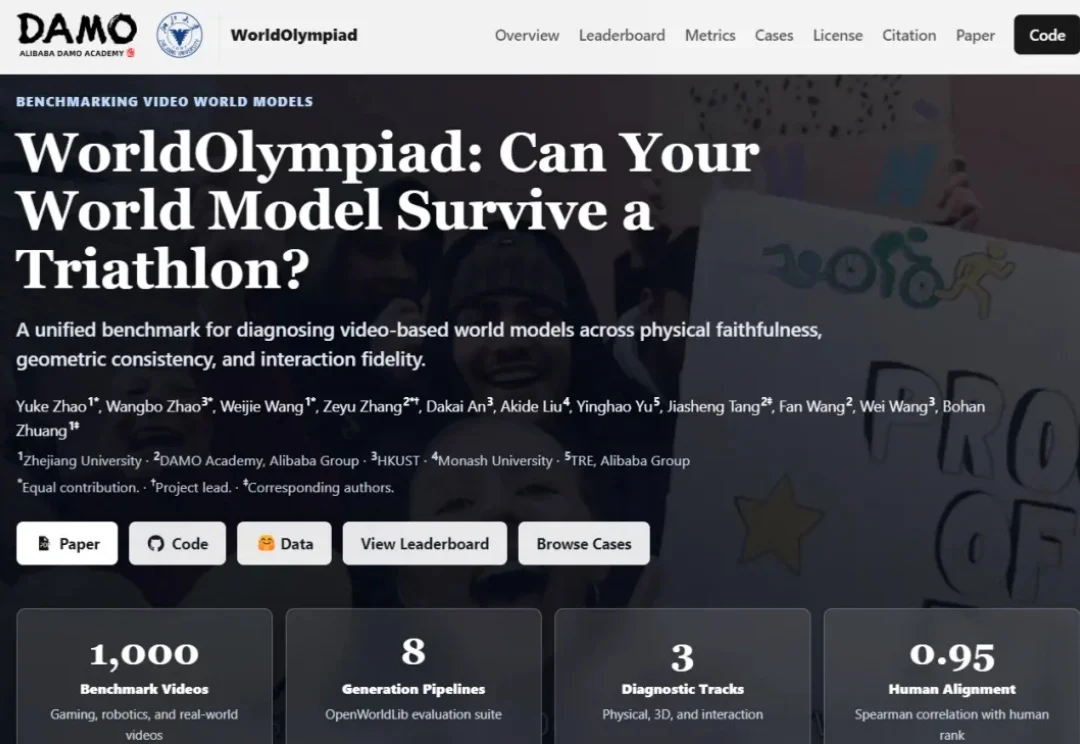
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。

偷师、借道、换血、误删……折腾到最后,xAI成了给对手供电的人。

卧槽,这事真的太抽象了。

AI 真正的终局之战,可能根本不在 C 端。过去两年,我们见证了无数个打着“个人助理”旗号的 AI 应用争夺流量入口,像极了移动互联网早期的百团大战。

刚刚被 SpaceX 宣布以 600 亿美元收购的 Cursor,发布大模型了。本周二,Cursor 宣布了一个新的 1.5 万亿 + 参数模型,该模型在超过 10 万块 GPU 上进行了预训练。消息是在旧金山举行的 Cursor Compile 上宣布的,这是 Cursor 举办的首届旗舰大会。

6 月初,一则关于爆款 AR 手游《精灵宝可梦 GO》(Pokémon GO,以下简称《宝可梦 Go》)的消息开始发酵:有报道称,Niantic(《宝可梦 Go》开发商)过去通过玩家收集的现实世界图像和空间数据,正被用于训练一种可能服务于无人机导航的人工智能系统,而合作方之一 Vantor 与军工、国防场景存在关联。

有两个站在硅谷最深处的AI天才,乔治·霍兹(George Francis Hotz)和卡帕西(Andrej Karpathy),为了AI编程这件事吵起来了,而他们背后,正是硅谷乃至美国AI市场的撕裂。