Juicebox:用 AI 把 HR 工作提效 2 倍,4 人团队实现 $10M ARR
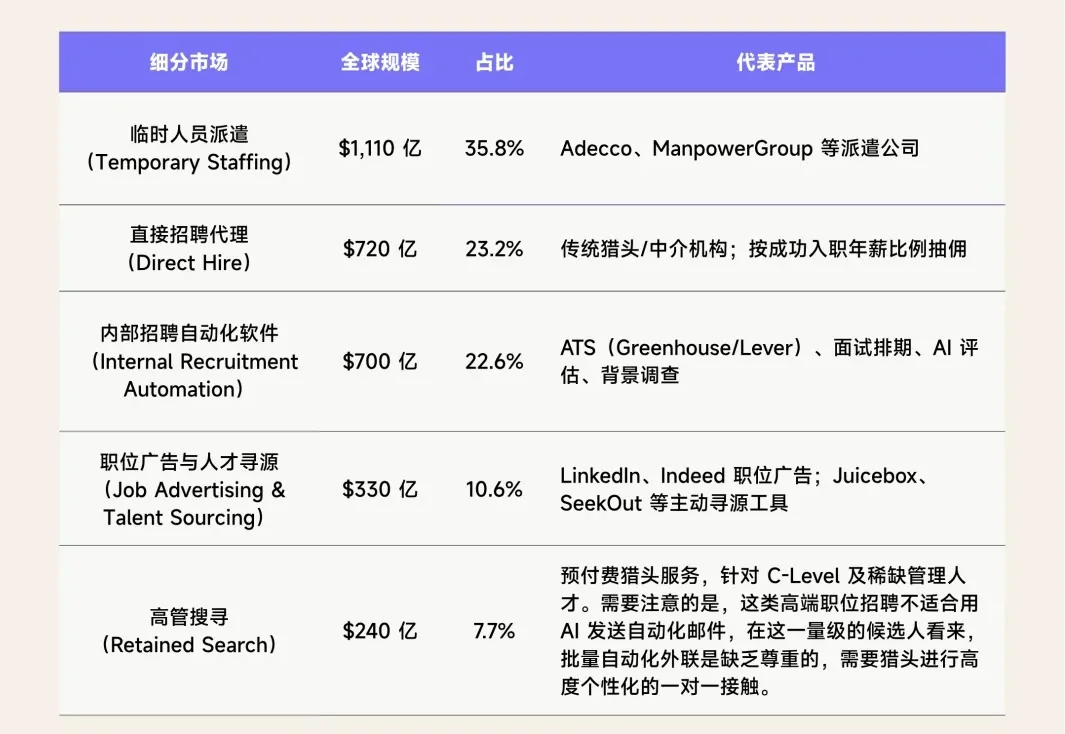
Juicebox:用 AI 把 HR 工作提效 2 倍,4 人团队实现 $10M ARR招聘是企业中信息损耗最严重的场景之一:从业务方描述“我需要能解决这个问题的人”,到 HR 翻译成关键词逐一筛选,每个环节都在吞噬语义信息。初级 HR 30%~50% 的工作日花在重复的搜索与外联上;AI 工具普及后,单个职位平均收到近 250 份申请,被动渠道的质量更加被稀释。
来自主题: AI资讯
7050 点击 2026-04-03 10:18