
柔体操作最缺数据、最怕仿真失真?新研究让布料物理真实再现
柔体操作最缺数据、最怕仿真失真?新研究让布料物理真实再现近年来研究者们一直在试图通过仿真环境批量产出具身训练数据。
来自主题: AI技术研报
6832 点击 2026-04-15 14:17
 搜索
搜索
近年来研究者们一直在试图通过仿真环境批量产出具身训练数据。
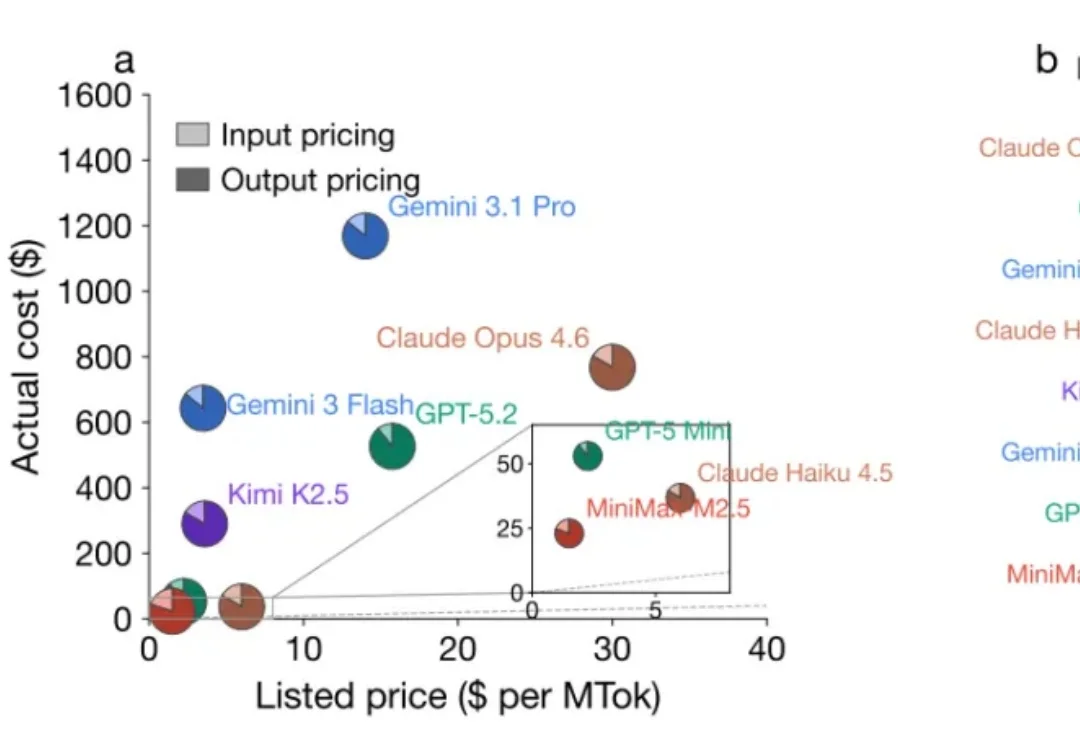
在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?

我们发布了TokenDance 词元跳动,一站式大模型 API 调用平台。希望能够赋能更多观猹生态内的 AI 企业、OPC 开发者与 AI 爱好者,帮助 AI 时代的创造者们,省一些成本,多一些创造。

据外媒The Information曝料,微软近期刚刚重组了Copilot工程团队,并计划靠“龙虾”(开源AI Agent框架OpenClaw的昵称)逆风翻盘。这一重大组织变革由CEO萨蒂亚·纳德拉(Satya Nadella)亲自操刀,被列为公司“头等优先事项”。他提拔高管并组建了一支12人精锐队伍,计划在Copilot中构建类OpenClaw的AI Agent产品,
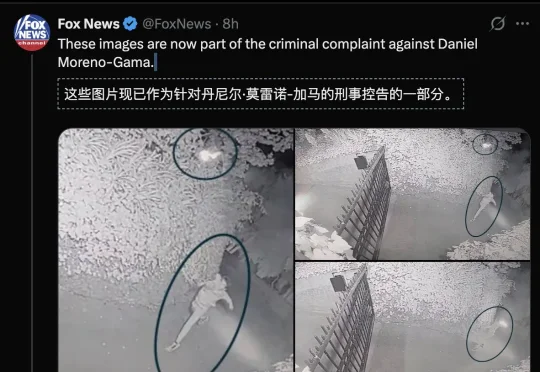
袭击奥特曼住宅的嫌疑犯,已被捕!科幻与现实的界限已模糊:当推动AI的人加速狂奔,恐惧AI的人举起火把——这场对抗,才刚刚进入最危险的阶段。

据知情人士透露,一家从哈佛大学独立出来的新型人工智能实验室正在与投资者进行谈判,以筹集约1 亿美元,以追求一项听起来像科幻小说的使命 :"一个人类可以记住一切的世界"。

近日,专注于精准健康与长寿医学的美国公司Human Longevity宣布,人工智能先驱、诺贝尔奖化学奖得主Geoffrey Hinton加入公司担任科学顾问。

多智能体赛道爆发,Harness成为破局关键,资本加速布局。

他还在开发一个CEO智能体。

文本驱动的人体动作生成是游戏NPC、虚拟主播、机器人控制等实时交互系统的核心技术。