

自变量机器人完成近20亿元B轮融资,小米战投、红杉中国领投
自变量机器人完成近20亿元B轮融资,小米战投、红杉中国领投唯一一家同时被四家互联网大厂(字节、美团、阿里、小米)投资的具身智能公司。
来自主题: AI资讯
8253 点击 2026-04-20 09:47
唯一一家同时被四家互联网大厂(字节、美团、阿里、小米)投资的具身智能公司。

4月19日中午,“2026北京亦庄半程马拉松暨人形机器人半程马拉松”落下了帷幕,本届比赛冠军,由荣耀齐天大圣队的“闪电”机器人摘得,并超过了人类男子半马世界纪录。

就在刚刚,2026北京亦庄机器人半程马拉松上,阿里巴巴旗下高德正式公开全球首款开放环境全自主具身机器人「高德途途」。这款四足机器人成功协助视障人士完成复杂避障、人群穿行等实战挑战,突破了「实验室」到「开放环境」之间的技术鸿沟。

上个月,智元刚刚跨过“机器人量产下线一万台”的门槛。4月17日,这家由前华为“天才少年”彭志辉与前华为副总裁邓泰华共同创立的机器人公司在合作伙伴大会上,花了大量的时间和篇幅介绍软件上的新产品。相较之下,硬件的篇幅反倒很少。
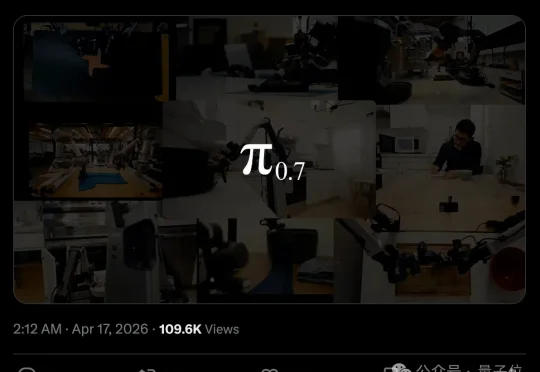
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。

香港城市大学朱宗龙、曾晓成团队给出了终极终结方案。他们首创了一套AI驱动的自动化闭环研发平台。从2万个分子的“大海捞针”,到自动化机械臂精准制备,再到AI实时反馈调整,全程无需人类插手。

具身智能领域论文被引次数最高的华人学者,带着十七年海外积淀,回来了。

具身智能的Scaling Law停滞了吗?

过去两年,具身智能最大的瓶颈,其实不是模型。

质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。